10. ニューラルネットワークの概要#
AI・機械学習などと称されるデータ分析手法・アルゴリズムの多くは 「入力データと出力データ間の非自明な関係を人工ニューラルネットワーク(Artificial Neural Networkm, ANN)と呼ばれる、ネットワーク構造を持つ関数によって模倣する」点が本質的である。
生物の神経回路網を模倣したANNの歴史は古く、遡ると1940年代頃から研究されている一方、 「ブームを迎えてはしばらくして下火になる」ということを二回ほど繰り返してきた歴史もある。
2000年代になり、計算機の発展やアルゴリズムの改良も手伝い、それまで計算量やデータの準備・処理上の問題で 現実的でなかった様々なタスク(音声・画像・自然言語などにおける処理やパターン認識等)に対して ANN及びそれを拡張したモデルが高い性能を発揮することがわかり、数多くの成功を収めるとともに、 2010年前後にはディープラーニングと称される一分野を形成するに至った。
様々な学術分野だけでなく、社会や産業にも浸透し、スマートフォンのカメラなど身近なところでも当たり前のように応用されている。 皆さんのお手元にスマートフォンがあれば、
画像認識技術を用いた認証システム (例:端末のロックを解除したり写真に写ったものと類似の商品を調べる)
画像生成技術を用いた写真の補正 (例:写真に写り込んだ人を消す)
自然言語処理を用いた翻訳・対話・botサービス (例:アシスタント系アプリや翻訳、自動音声)
といったことを当たり前のようにやってのけるハード・ソフト/Webサービス等が既にあるのをご存知だろう。
特に、2022年にChatGPTが発表されて以降、画像や動画・音声、自然言語処理などのタスクを高い精度でこなす生成AIの登場が社会に大きなインパクトを覚えた。 これらの背景にあるのも、ニューラルネットワークの発展形である。
この授業では、機械学習手法の根幹を支えるニューラルネットワークについて、基本的な動作原理を理解することを目標に、 主に3層(入力層・隠れ層・出力層)からなる最も単純な構造を持ったニューラルネットワークを題材として説明を行う。 単純なモデルに注目して理解しておくことは、皆さんが機械学習分野の基礎(理論)あるいは応用に際してより複雑なアーキテクチャを仕様・理解する上での基礎となるはずだ。
10.1. パーセプトロン#
まず、ニューラルネットワークの基本的な要素となるパーセプトロン(Perceptron)を紹介する。 パーセプトロンは1957年に考案された模型で、ニューラルネットワークの一種(特殊な場合)とみなせる。
下図のように、あるノード(節)に注目した際、そのノードに\(n\)個の入力信号があり、一つの値を出力するケースを考える。
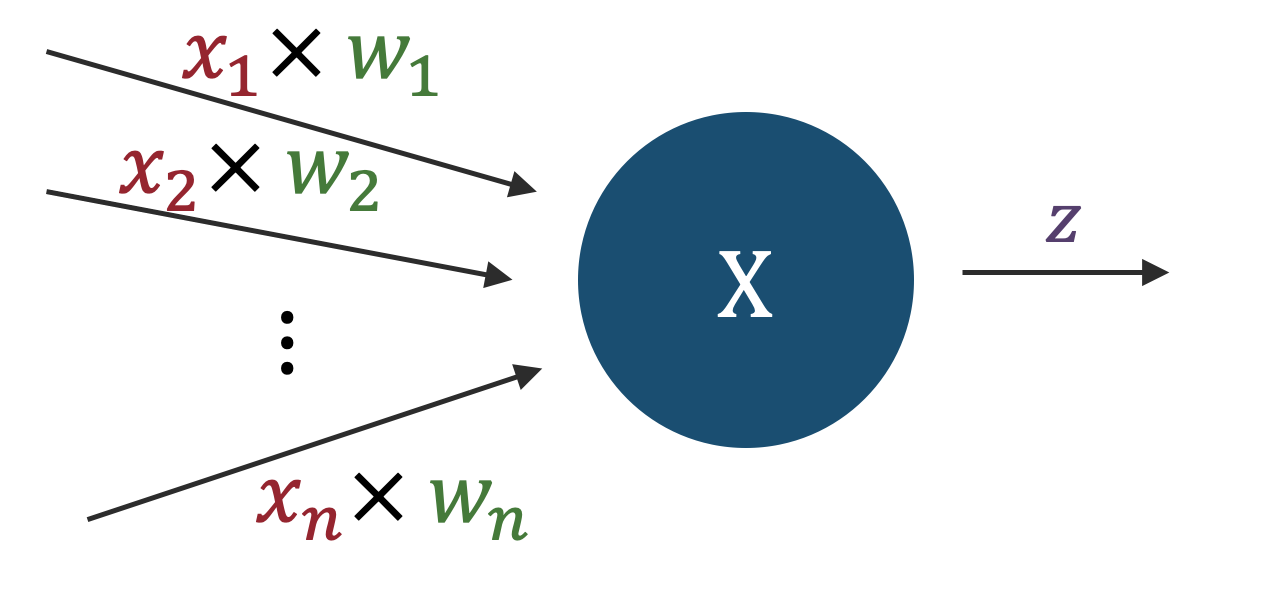
便宜上、入力信号の数を\(n\)とし、それぞれの入力信号を\(x_1,x_2,...,x_n\)のように\(n\)成分を持つベクトルの各成分のように書くことにする。 また、入力信号を"受け取る"重みを\(w_1,w_2,...,w_n\)のように書くことにする。 重みは、入力信号の重要度を表すパラメータであり、重みが大きいほどその入力信号の重要度が高いことを意味する。
このとき、今注目しているノードに対する全入力信号\(X\)は、\(X=x_1w_1+x_2w_2+...+x_nw_n\)あるいはベクトルの内積として\(X=\boldsymbol{w} \cdot \boldsymbol{x}\)と書くことができる。 この\(X\)の値がある閾値(しきい値,threshold)\(\theta\)を超えた場合に、ノードの出力\(z\)は\(1\)、超えなかった場合には\(0\)となる、と約束する。 式で書くと、
となる。この関数は、ある種の信号伝達を担う"関所"のようなものになっていて、 「自身への入力信号の重み付き和がある値を超えた場合にのみ、次のノードに信号を伝達する」という働きをする。
適当に\(\theta=2.0\)として、コードでプロットしてみよう
Show code cell source
import matplotlib.pyplot as plt
def plot_stepfunc(theta=2.0):
fig = plt.figure()
plt.scatter(2,1,marker="o",color="k")
plt.plot([-6,2],[0, 0],color="k")
plt.plot([2,10],[1, 1],color="k")
plt.ylabel("$f(X)$")
plt.xlabel("$X$")
plt.show()
plt.close()
plot_stepfunc()
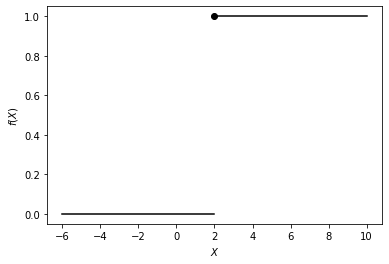
このようなノードをパーセプトロンと呼ぶ。 ノードの出力は0か1の離散的な2値をとるため、True/Falseのような真偽値とみなすこともできる。
入出力の具体的な例として、100×100ピクセルの画像を入力として受け取り、その画像が犬の画像であるかどうかを判定するパーセプトロンを考える。 各ピクセルの画素値を10000成分を持つベクトルの成分とみなし\(x_1,x_2,...,x_{10000}\)とし、 それぞれの入力に対する重みを\(w_1,w_2,...,w_{10000}\)とする。このとき、パーセプトロンの出力は、
となり、重みと閾値の値を"うまく調整してやれば"、与えられた画像が犬の画像かどうかの判定ができると原理的には考えられる。
だが実際には「各ピクセルの画素値の重み付き和」が閾値を超えるかどうかで判定するというのは、 画像の特徴を捉えるのにはあまり適していないと予想ができる。 なぜなら、例えば犬の画像の場合、犬の画像の特徴は画像の中のどこにあるかによっても異なるし、 犬が写っているかを判断する上では、上下左右に隣り合うピクセル同士の関係なども重要になるのに対して、 上記のようなパーセプトロンでは、各ピクセルの画素値の重み付き和しか見ていないからである。
10.2. ニューラルネットワーク: 全結合#
次にニューラルネットワークの最も単純な例として、全結合のニューラルネットワークを紹介する。 全結合のニューラルネットワークは、パーセプトロンのノードを層状に並べたもので、 隣り合う層のノード間には全て結合があるというものである。 図で見るほうがはやいので以下に示そう。
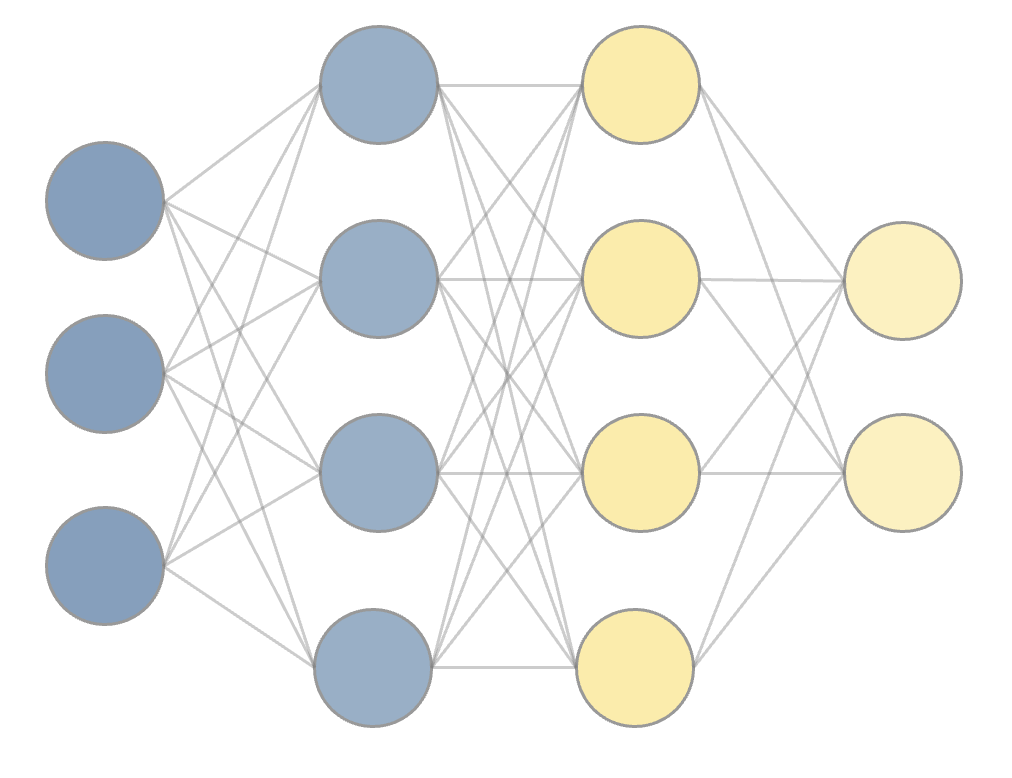
上のパーセプトロンのように、1つのノードに着目してみよう。 ニューラルネットワークの各ノードで行う操作は、
入力信号\(x\)の重み付き和を計算し、バイアス項\(b\)を加える
重み付き和+バイアスを活性化関数\(g\)に入力して、活性化関数の出力を計算する
出力を次の(下流の)ノードに伝達する
という3つになる。この内、パーセプトロンを"より拡張した"考え方が1.と2.に含まれている。 あるノードに対する入力が\(x\)、重みが\(w\)(それぞれ長さ\(n\)のベクトルとする)、バイアスが\(b\)で与えられているとき、上の操作を式で書くと、
となる。
1.の重み付き和を計算する部分は、パーセプトロンと同じである。 バイアス(bias)は、各ノードにおいて、入力信号に対して計算された重み付き和に各ノード固有の定数を加えることに対応している。
実際には、ノードや層が複数定義されているため、より正確に式で書くと以下のようになる: 第\(l\)層の\(k\)番目のノードに着目した際の出力を\(z_k^{(l)}\)と表記することにすると、
と書くことができる。 単一のノードに着目するのではなく、単一の層に着目する表記に直すには \(l\)層のノードの数\(n_{l}\)を用いて、各ノードの出力をベクトルの成分、重みを行列の成分として表記するとよい:
それぞれの重み \(W^{(l)}\) は、ノードへの入力の次元(\(n_{l-1}\))×ノードからの出力の次元(\(n_{l}\))を持つ行列である。 各ノードで行なう \(Wz + b\) の計算は、線形変換と平行移動に相当する演算で、より一般にはAffine変換と呼ばれる。このことから、全結合ニューラルネットワークのことをAffine Layerなどと呼ぶこともある。 あるいは、パーセプトロンを組み合わせたものとして、 多層パーセプトロン(Multi-Layer Perceptron, MLP) と呼ぶこともある。
2.の操作に現れた活性化関数については、後で詳しく述べるが、 入力の重み付き和(+バイアス)に対して、非線形な関数を適用することで、 より複雑な関数を表現することができるようになる。 パーセプトロンは、この活性化関数が単純なステップ関数である場合に相当する。
パーセプトロンと上のニューラルネットワークの大きな違いは、構造や一般化(バイアス・活性化関数)はもちろんだが、 各ノードの出力が0か1の2値ではなく任意の実数をとりうる(つまり出力の値も一般化している)ことである。 これにより、最終的な出力を2値だけに限定することなく、 より複数の"クラス"に対する真偽値を判定する、あるいは連続値を出力しクラスに属する"確率"を計算する、 ピクセルの画素値を推定する、といった、より複雑な出力に対応することができる。
ニューラルネットワークにおける訓練あるいは学習とは、入力データを用いて、出力と正解の差を最小化するように、 各ノードの重みやバイアスを調整(≒最適化)することと言い換えられる。
10.3. 活性化関数#
次に、活性化関数について説明する。 ニューラルネットワークのノードにおいて、重み付き和(+バイアス)に対して適用する関数を活性化関数と呼ぶ。 パーセプトロンの場合は、活性化関数はステップ関数であったが、 ニューラルネットワークでは、ステップ関数以外の様々な関数が用いられる。
活性化関数には、例えば以下のようなものがある:
シグモイド関数
\[g(u) = \frac{1}{1 + \exp(-u)}\]Tanh関数
\[g(u) = \frac{\exp(u) - \exp(-u)}{\exp(u) + \exp(-u)}\]ReLU関数
\[g(u) = \max(0, u)\]Leaky ReLU, ELUなどその他にも派生を持つ。ReLUは、現代的なニューラルネットワークでは、最もよく用いられる活性化関数の一つである。
恒等関数(回帰問題の出力層で用いる。)
\[g(u) = u\]ソフトマックス関数
主に分類問題において、各クラスに属する確率を出力するために用いられる
\[g(u_i) = \frac{\exp(u_i)}{\sum_{j=1}^n \exp(u_j)}\]
活性化関数は、ニューラルネットワークの学習において重要な役割を果たす。 入力と出力の間の一般には非線形な関係を表現するために用いられ、 タスクに応じて、予測精度の高い適切な活性化関数を選択することが重要である。
例えば上のReLU関数は、近年の深層学習モデルの中でも最もよく利用されている活性化関数の1つである。 ReLUには、勾配の計算が自明なことによる計算量的利点と、勾配消失の問題を低減する効果があるため、 画像認識などネットワークの構造が"深い"ニューラルネットワークで効率的に学習をすすめるために採用されることが多い。
10.3.1. 活性化関数の役割#
活性化関数の役割について1つ注を添えておこう。 例えば、3層のニューラルネットワークを用いて、単純な回帰問題を解く、つまり \(\boldsymbol{y}=f(\boldsymbol{x})\)という"真の関数"をニューラルネットワークの出力\(f^{NN}(\boldsymbol{x})\)を用いて近似することを考える。 表式を簡素にするため、各ノードでのバイアス項を省略して考えることにすると、 上記のようなニューラルネットワークは、以下のように表せる。
この場合、対象となる問題は回帰問題に分類されるため、出力層における活性化関数\(g_2\)は恒等関数を用いる。 では、隠れ層における活性化関数\(g_1\)を上のようなTanhやReLUではなく恒等関数を用いた場合、何が起こるだろうか?
この場合のニューラルネットワークの出力は
となり、層を繰り返すことによって得られる信号の変換は単なる行列の積となり、 単一の行列\(\tilde{W}= \boldsymbol{W}_2 \boldsymbol{W}_1\)による線形変換になってしまう。
つまり、隠れ層の活性化関数を恒等関数にすると、いくら隠れ層を増やしても 線形変換による近似しかできないため、ニューラルネットワークの表現力が制限されてしまう。 入力と出力の間の非線形な関係を表現するためには、隠れ層において非線形な活性化関数を用いることが本質的である。
問題:
以下の活性化関数と微分を計算し、グラフの全容が分かる範囲でグラフを描け:
シグモイド関数
\[g(u) = \frac{1}{1 + \exp(-u)}\]Tanh関数
\[g(u) = \frac{\exp(u) - \exp(-u)}{\exp(u) + \exp(-u)}\]ReLU関数
\[g(u) = \max(0, u)\]
問題:
上の活性関数とその微分から、多層ニューラルネットワークにおける勾配消失の問題について説明せよ。 とくに、多層にした際に伝播される信号(勾配)のサイズが層の数に対して典型的にどう変化するかの観点から説明せよ。
10.4. \(\clubsuit\) ニューラルネットワークを用いた手書き数字データの分類#
多クラス分類の章で扱ったMNIST(手書き数字)データの分類に対して、線形分類の部分を多層パーセプトロン(ニューラルネットワーク)に置き換えたモデルを構築し、分類精度がどうなるかを確認してみよう。
以下では、隠れ層が2層の多層パーセプトロンと、畳み込みニューラルネットワーク(CNN)の2つのモデルを構築してみた。
Show code cell source
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# 1. データセットの準備 (MNIST, 28x28 画像, 0~9 のラベル)
transform = transforms.Compose([transforms.ToTensor(), # 画像をTensor化
transforms.Normalize((0.5,), (0.5,))]) # 正規化
trainset = torchvision.datasets.MNIST(root="./data", train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.MNIST(root="./data", train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=1000, shuffle=False)
# 2. 多層パーセプトロン (MLP)
class MultiLayerPerceptron(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(28*28, 128) # 入力層 → 隠れ層1
self.fc2 = nn.Linear(128, 64) # 隠れ層1 → 隠れ層2
self.fc3 = nn.Linear(64, 10) # 隠れ層2 → 出力層
self.relu = nn.ReLU() # ReLU活性化関数
def forward(self, x):
x = x.view(-1, 28*28) # (batch, 1, 28, 28) → (batch, 784)
x = self.relu(self.fc1(x)) # 隠れ層1 + ReLU
x = self.relu(self.fc2(x)) # 隠れ層2 + ReLU
x = self.fc3(x) # 出力層
return x
model = MultiLayerPerceptron()
# 3. 損失関数と最適化手法
criterion = nn.CrossEntropyLoss() # Softmax + CrossEntropy
optimizer = optim.Adam(model.parameters())
# 4. 学習ループ
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
for images, labels in trainloader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {running_loss/len(trainloader):.4f}")
# 5. テスト精度の評価
correct = 0
total = 0
with torch.no_grad():
for images, labels in testloader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Test Accuracy: {100 * correct / total:.2f}%")
# 6. いくつかのテストデータで予測を表示
dataiter = iter(testloader)
images, labels = next(dataiter)
# モデルの予測
outputs = model(images)
_, predicted = torch.max(outputs, 1)
# 最初の10枚を表示
fig, axes = plt.subplots(1, 10, figsize=(15, 2))
for i in range(10):
axes[i].imshow(images[i].squeeze(), cmap="gray")
axes[i].set_title(f"P:{predicted[i].item()}\nT:{labels[i].item()}")
axes[i].axis("off")
plt.show()
Epoch 1/10, Loss: 0.3866
Epoch 2/10, Loss: 0.1870
Epoch 3/10, Loss: 0.1336
Epoch 4/10, Loss: 0.1076
Epoch 5/10, Loss: 0.0899
Epoch 6/10, Loss: 0.0813
Epoch 7/10, Loss: 0.0723
Epoch 8/10, Loss: 0.0607
Epoch 9/10, Loss: 0.0602
Epoch 10/10, Loss: 0.0522
Test Accuracy: 96.92%

Show code cell source
# 畳み込みニューラルネットワーク (CNN)
class ConvolutionalNeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
# 畳み込み層
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1) # 28x28 -> 28x28
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1) # 14x14 -> 14x14
self.pool = nn.MaxPool2d(2, 2) # プーリング層
self.dropout1 = nn.Dropout(0.25)
# 全結合層
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.dropout2 = nn.Dropout(0.5)
self.fc2 = nn.Linear(128, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.conv1(x)) # 畳み込み1 + ReLU
x = self.pool(x) # プーリング (28x28 -> 14x14)
x = self.relu(self.conv2(x)) # 畳み込み2 + ReLU
x = self.pool(x) # プーリング (14x14 -> 7x7)
x = self.dropout1(x)
x = x.view(-1, 64 * 7 * 7) # 平坦化
x = self.relu(self.fc1(x)) # 全結合層1 + ReLU
x = self.dropout2(x)
x = self.fc2(x) # 出力層
return x
# CNNモデルのインスタンス化
cnn_model = ConvolutionalNeuralNetwork()
# 損失関数と最適化手法
cnn_criterion = nn.CrossEntropyLoss()
cnn_optimizer = optim.Adam(cnn_model.parameters())
# 学習ループ
cnn_epochs = 10
for epoch in range(cnn_epochs):
running_loss = 0.0
for images, labels in trainloader:
cnn_optimizer.zero_grad()
outputs = cnn_model(images)
loss = cnn_criterion(outputs, labels)
loss.backward()
cnn_optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{cnn_epochs}, Loss: {running_loss/len(trainloader):.4f}")
# テスト精度の評価
correct = 0
total = 0
with torch.no_grad():
for images, labels in testloader:
outputs = cnn_model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"CNN Test Accuracy: {100 * correct / total:.2f}%")
# いくつかのテストデータで予測を表示
dataiter = iter(testloader)
images, labels = next(dataiter)
# CNNモデルの予測
outputs = cnn_model(images)
_, predicted = torch.max(outputs, 1)
# 最初の10枚を表示
fig, axes = plt.subplots(1, 10, figsize=(15, 2))
for i in range(10):
axes[i].imshow(images[i].squeeze(), cmap="gray")
axes[i].set_title(f"P:{predicted[i].item()}\nT:{labels[i].item()}")
axes[i].axis("off")
plt.show()
Epoch 1/10, Loss: 0.2493
Epoch 2/10, Loss: 0.0952
Epoch 3/10, Loss: 0.0717
Epoch 4/10, Loss: 0.0609
Epoch 5/10, Loss: 0.0523
Epoch 6/10, Loss: 0.0482
Epoch 7/10, Loss: 0.0413
Epoch 8/10, Loss: 0.0385
Epoch 9/10, Loss: 0.0357
Epoch 10/10, Loss: 0.0350
CNN Test Accuracy: 98.68%
2000年代初頭には既に、多層パーセプトロンを用いて誤判定率1%以下を達成する研究が報告されていたが、その後、畳み込みニューラルネットワークを初めとする深層学習のモデルにより、0.3%以下という非常に高い精度が達成されている。
上では、計算時間の関係でモデルサイズや学習エポック数を抑えているため、誤判定率が数%とあまり精度は高くないが、様々な工夫を凝らすことで、より高い精度を達成することも可能である。 また、GPUが利用できれば、より大きなモデルを効率的に学習させることができ、Google Colabなどのクラウドサービスを利用するのも一つの手である。