12. 機械学習における最適化#
この章では、最適化手法、中でもニューラルネットワークの訓練のための連続最適化手法を中心に解説する。 機械学習における最適化は、それだけで教科書が存在するほど奥の深い分野であり、本章では基本的な考え方と代表的な手法を紹介するにとどめる。
実際の機械学習モデルの訓練・学習においては、PyTorchなどのフレームワークに実装されている最適化手法を利用することが多く、様々な最適化手法を試しながら最適な手法を選択することが多い。 論文などで新たな最適化手法が提案されてすぐにPyTorchなどに実装されることもあり、この分野の発展の速さがうかがえる。
以下では、機械学習モデルにあるパラメータ(例えば、MLPの場合重みやバイアス)を\(\theta\)、訓練データを\(\{(x_i, y_i)\}_{i=1}^N\)とし、損失関数を\(L(\theta; \{(x_i, y_i)\}_{i=1}^N)\)などと表す。
12.1. 誤差関数の多峰性#
機械学習における最適化の難しさを理解するうえで重要な概念が、多峰性である。 多峰性とは、誤差関数が複数の極小値(ローカルミニマム)を持つ性質を指す。 ニューラルネットワークのような複雑なモデルでは、誤差関数が非常に複雑な形状を持ち、多くの極小点が存在する場合が多い。 そうした状況で、単純な最適化手法(例えば、勾配降下法)を用いると、初期値に依存して局所的な極小点に陥りやすく、真の最適解に到達できず、学習をいくら続けてもモデルの性能が向上しないことがある。
そこで行われる様々な工夫が、最適化手法の改良である。あるいは、誤差関数の形状を改善するための手法(例えば、正則化やバッチ正規化など)なども重要である。
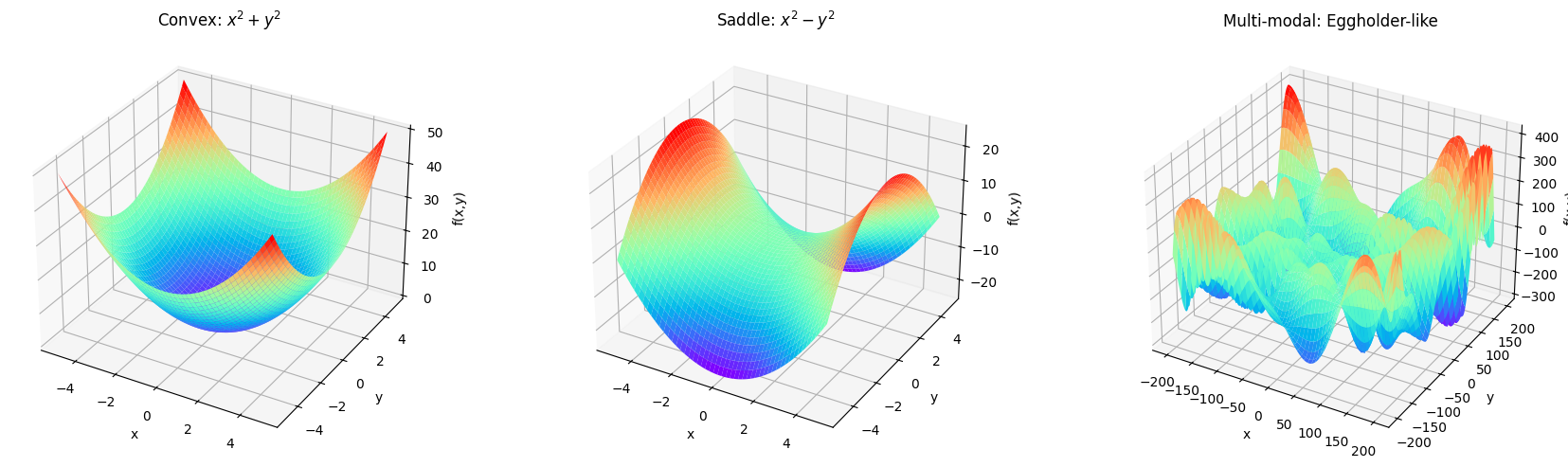
絵があったほうが視覚的なイメージが進むと思うので、凸関数や多峰性のある関数の例を幾つか示しておこう。 とはいっても人間には3次元以上の関数のイメージは難しいので、パラメータが2次元の場合について考える。
以下では、
convex関数の例: \(f(x, y) = x^2 + y^2\)
鞍点を持つ関数の例: \(f(x, y) = x^2 - y^2\)
多峰性を持つ関数の例: \(f(x, y) = -(y+47) \sin(\sqrt{|y+x/2+47|}) - x \sin(\sqrt{|x-(y+47)|})\) (Eggholder function)
の3つを示す。
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # noqa: F401
# Grid
x = np.linspace(-5, 5, 200)
y = np.linspace(-5, 5, 200)
X, Y = np.meshgrid(x, y)
x_e = np.arange(-200, 200, 1)
y_e = np.arange(-200, 200, 1)
X_e, Y_e = np.meshgrid(x_e, y_e)
# Functions
Z_convex = X**2 + Y**2
Z_saddle = X**2 - Y**2
Z_eggholder = (
-(Y_e + 47) * np.sin(np.sqrt(np.abs(X_e/2 + (Y_e + 47))))
- X_e * np.sin(np.sqrt(np.abs(X_e - (Y_e + 47))))
)
fig, axs = plt.subplots(1, 3, figsize=(18, 5), subplot_kw={'projection': '3d'})
surf_kwargs = dict(rcount=60, ccount=60, cmap='rainbow', linewidth=0, antialiased=True)
axs[0].plot_surface(X, Y, Z_convex, **surf_kwargs)
axs[0].set_title("Convex: $x^2+y^2$")
axs[0].set_xlabel('x'); axs[0].set_ylabel('y'); axs[0].set_zlabel('f(x,y)')
axs[1].plot_surface(X, Y, Z_saddle, **surf_kwargs)
axs[1].set_title("Saddle: $x^2-y^2$")
axs[1].set_xlabel('x'); axs[1].set_ylabel('y'); axs[1].set_zlabel('f(x,y)')
axs[2].plot_surface(X_e, Y_e, Z_eggholder, **surf_kwargs)
axs[2].set_title("Multi-modal: Eggholder-like")
axs[2].set_xlabel('x'); axs[2].set_ylabel('y'); axs[2].set_zlabel('f(x,y)')
plt.tight_layout()
plt.show()
12.2. 勾配降下法#
勾配降下法(Gradient Descent, GD)は、関数の最小値を見つけるための最も基本的な最適化手法である。
関数\(f(\boldsymbol{\theta})\)の勾配\(\nabla f(\boldsymbol{\theta})\)は、関数が最も急激に増加する方向を示すベクトルであり、 勾配降下法ではこの勾配の反対方向にパラメータ\(\boldsymbol{\theta}\)を更新することで、関数の値を減少させる、というのが基本的な考え方である。
最も単純なものが最急降下法であり、パラメータ\(\boldsymbol{\theta}\)の更新は以下のように行われる。
ここで、\(L\)は目的関数で、\(\eta\)は学習率(パラメータ更新のスケールを決めるパラメータ)とした。 いま、逐次的にパラメータを更新していくことを想定し、\(t\)は更新ステップを表している。
ANN(MLP)の最適化においてはしばし、訓練データを小さなサブ集合(ミニバッチ)に分割し、各ミニバッチに対して勾配降下法を適用することが行われる。 加えて、全体・あるいはミニバッチの中からランダムにサンプルを選ぶなどする方法もあり、これを 確率的勾配降下法(Stochastic Gradient Descent, SGD) と呼ぶ。 バッチに分けることで、各ステップでの計算コストが削減される上に並列計算が可能になる。 また、固定のデータを常に用いるよりも、ある種のノイズが導入され、局所最適解から脱出できることがある。
バッチサイズ\(|B|\)はミニバッチのサンプル数である。とくに\(|B|=1\)の場合をオンライン学習(online learning)と呼んだりもする。
SGDなどの勾配法はシンプルで実装も容易であるが、中々収束しない、局所最適解に陥りやすい、などの問題が生じることもある。加えて学習率をどのように設定するのかが非自明である。 データの特性に応じて、学習をステップに分けて学習率を変更させたり、指数関数や多項式を用いて学習が進むにつれて小さな学習率に変更するなどの工夫もなされてきたが、最適な学習率のスケジュールを見つけるのは一般に難しい。
そうした経緯から提案されたのが、勾配だけでなく、過去の更新情報を利用するモーメンタム法や、パラメータごとに異なる学習率を適応的に調整するAdaGrad, RMSProp, Adamなどの手法である。 年代に沿ってこれらの手法を紹介するのも楽しいが、続く節では、現代においても広く用いられているAdamを中心に説明する。
大雑把にいうと、モーメンタム法はそれまでの勾配の移動平均を計算し、その方向にパラメータを更新する手法である。これにより、勾配が振動する方向では更新が抑制され、安定した更新が可能になる。AdaGradやRMSPropは、各パラメータに対して異なる学習率を適応的に調整する手法であり、頻繁に更新されるパラメータの学習率を減少させ、まれに更新されるパラメータの学習率を増加させることで、効率的な学習を実現する。 Adamは、モーメンタム法とRMSPropの両方のアイデアを組み合わせた手法であり、各パラメータに対して適応的な学習率を計算しつつ、過去の勾配情報も考慮することで、効率的かつ安定した学習を実現する。
12.2.1. \(\clubsuit\) モーメンタム法#
勾配とは別に、その指数移動平均\(v_t\)を計算し、これを用いてパラメータを更新する。 谷に向かって転がしたボールの慣性を考慮するイメージである。
\(\beta\)は過去の勾配情報をどの程度考慮するかを決めるハイパーパラメータになっていて、\(\beta=0\)の場合は通常の勾配降下法と同じになる。
12.2.2. \(\clubsuit\) AdaGrad#
勾配の二乗の移動平均を計算し、これを用いてパラメータごとに異なる学習率を適応的に調整する。
ベクトルの要素ごとの積を\(\odot\)で表している。\(\epsilon\)はゼロ除算を防ぐための小さな定数である。 \(s_t\)が大きくなると学習率が小さくなるため、頻繁に更新されるパラメータの学習率が減少し、まれに更新されるパラメータの学習率が増加する効果がある。
12.2.3. \(\clubsuit\) RMSProp#
勾配の二乗の指数移動平均を計算し、これを用いてパラメータごとに異なる学習率を適応的に調整する。
\(\beta \in [0, 1)\)を導入することで、過去の勾配情報を指数的に減衰させる効果がある。
12.3. Adam#
Adamは、勾配降下法の様にその都度の勾配の情報だけを使うのではなく、以前の勾配の情報も有効活用しながら学習率も調整する手法である。
2014年にDiederik P. KingmaとJimmy Baによって提案されて以来、深層学習の分野で現代に至るまで広く用いられている。→arXiv:1412.6980
Adamでは、各パラメータ\(\theta_i\)に対して、以下のように更新を行う。
なお\(m_t, v_t\)はそれぞれ1次モーメンタム、2次モーメンタムと呼ばれ、element-wiseに計算する(つまり、各パラメータごとに計算しベクトルとして保持する)。 \(\beta_1, \beta_2\)はそれぞれ1次モーメンタム、2次モーメンタムの減衰率を表すハイパーパラメータであり、よく\(\beta_1=0.9, \beta_2=0.999\)が用いられる。 実際の更新式に用いるハット付きの量は、初期値を0に設定した場合のバイアスを補正するためのものである。
一次モーメント\(m_t\)は、勾配の指数移動平均を表し、過去の勾配情報を蓄積することで、勾配のノイズを平滑化し、安定した更新を可能にする。 二次モーメント\(v_t\)は、勾配の二乗の指数移動平均を表し、各パラメータの勾配の大きさを捉える。 これにより、勾配の大きさに応じて学習率を調整し、勾配が大きいパラメータの更新を抑制し、勾配が小さいパラメータの更新を促進する。
12.3.1. AdamW#
AdamWは、Adamの変種であり過学習を防止するための正則化手法であるWeight decay(重み減衰)を組み込んだものである。 SGDにおけるWeight decayは、パラメータの大きさを抑制することで過学習を防止する手法であり、L2正則化と等価になるが、Adamに対して単純にパラメータ更新の式にL2正則化項を加えてしまうと、重み減衰の効果が正しく働かないことが指摘され、そこで提案されたのがAdamWである。
AdamWの論文は、2017年にLoshchilovとHutterによって発表されたarXiv:1711.05101。
SGDにおけるWeight decayは、パラメータ更新の際の勾配に正則化項の勾配を加えることで実現される。
これは、誤差関数\(L_t\)に対してL2正則化項\(\frac{\lambda}{2} ||W||^2\)を加えたものを考えて勾配を計算していることに相当する。 この方法とのアナロジーで、Adamにおける勾配の計算に正則化項の勾配を加えることで正則化が期待できるが、Adamの更新式は勾配の大きさに応じて学習率を調整するため、正則化項の効果が不均一になり、期待通りに働かないことがある。
そこで、AdamWでは、Weight decayをパラメータ更新の際に直接適用することで、正則化の効果を均一に保つようにしている。
12.4. 二階微分を用いる方法#
勾配のみを用いる手法は、関数の形状に関する情報が限られているため、収束が遅い、局所最適解に陥りやすい、などの問題がある。これに対処するために、ヘッセ行列を用いた二階微分の情報を活用する方法がある。 二階微分の情報を用いることで、関数の曲率に関する情報を得ることができ、より効率的な最適化が可能になる。 一方で、ヘッセ行列の計算は計算コストが高く、特に高次元のパラメータ空間では実用的でないことが多い。
代表的な手法として、ニュートン法や準ニュートン法(L-BFGS法, etc.)などがある。 ニュートン法では、ヘッセ行列の逆行列を用いてパラメータを更新するのに対して、 準ニュートン法では、ヘッセ行列の近似を用いることで計算コストを削減する違いがある。
12.5. 二次元損失関数の最適化#
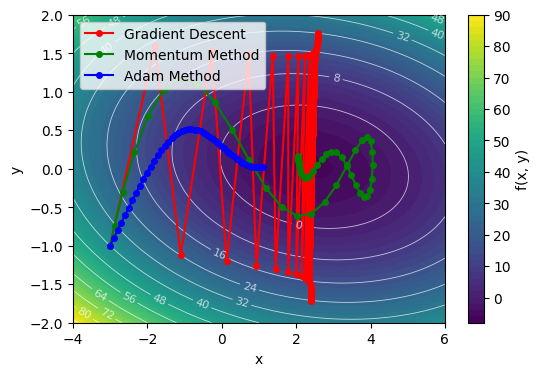
ここで、二次元の損失関数を例に、最適化手法の挙動を可視化してみよう。
適当な開始点 \((x_0, y_0)\) から始めて、勾配降下法、モーメンタム法、Adamで最適化を行い、その軌跡を可視化してみる。
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
def f(x, y):
return 0.5 * (2*x**2 + 2*x*y + 20*y**2) - (5*x + 3*y)
def grad_f(x, y):
dfdx = 2*x + y - 5
dfdy = x + 20*y - 3
return np.array([dfdx, dfdy])
# 最適化手法の実装
def gradient_descent(start, lr, steps):
x, y = start
path = [(x, y)]
for _ in range(steps):
grad = grad_f(x, y)
x -= lr * grad[0]
y -= lr * grad[1]
path.append((x, y))
return np.array(path)
def momentum_method(start, lr, steps, beta=0.9):
x, y = start
path = [(x, y)]
v = np.array([0.0, 0.0])
for _ in range(steps):
grad = grad_f(x, y)
v = beta * v + (1 - beta) * grad
x -= lr * v[0]
y -= lr * v[1]
path.append((x, y))
return np.array(path)
def adam_method(start, lr, steps, beta1=0.9, beta2=0.999, epsilon=1e-8):
x, y = start
path = [(x, y)]
m = np.array([0.0, 0.0])
v = np.array([0.0, 0.0])
for t in range(1, steps + 1):
grad = grad_f(x, y)
m = beta1 * m + (1 - beta1) * grad
v = beta2 * v + (1 - beta2) * (grad ** 2)
m_hat = m / (1 - beta1 ** t)
v_hat = v / (1 - beta2 ** t)
x -= lr * m_hat[0] / (np.sqrt(v_hat[0]) + epsilon)
y -= lr * m_hat[1] / (np.sqrt(v_hat[1]) + epsilon)
path.append((x, y))
return np.array(path)
# パラメータ設定
start = (-3.0, -1.0)
lr = 0.1
steps = 50
# 最適化の実行
gd_path = gradient_descent(start, lr, steps)
mom_path = momentum_method(start, lr, steps)
adam_path = adam_method(start, lr, steps)
# 可視化
x = np.linspace(-4, 6, 100)
y = np.linspace(-2, 2, 100)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
fig, ax = plt.subplots(figsize=(6, 4))
cf = ax.contourf(X, Y, Z, levels=50, cmap=cm.viridis)
c = ax.contour(X, Y, Z, levels=15, colors='w', linewidths=0.6, alpha=0.7)
ax.clabel(c, inline=True, fontsize=8)
fig.colorbar(cf, ax=ax, label='f(x, y)')
ax.plot(gd_path[:, 0], gd_path[:, 1], '-o', color='r', markersize=4, label='Gradient Descent')
ax.plot(mom_path[:, 0], mom_path[:, 1], '-o', color='g', markersize=4, label='Momentum Method')
ax.plot(adam_path[:, 0], adam_path[:, 1], '-o', color='b', markersize=4, label='Adam Method')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend()
plt.show()
12.6. 勾配消失を避けるための種々の工夫#
2010年代〜2020年代における深層学習の発展に伴い、勾配消失問題を避けるための様々な工夫が提案されてきた。 その中には、前述のような最適化手法の改良や活性化関数の提案も含まれるが、以下では、より現代的なアーキテクチャで採用されている方法をかいつまんで紹介する。
12.6.1. 正規化#
機械学習における 正規化 (Normalization) は、複数の文脈で用いられる用語で、
データの前処理としての正規化: 特徴量を特定のスケールに変換すること(例えば、平均0、分散1にするなど)。
バッチ正規化 (Batch Normalization): ネットワークの中間層の出力を正規化する手法。
レイヤー正規化 (Layer Normalization): バッチ正規化の代わりに、各サンプルの特徴量を正規化する手法。
などがある。
バッチ正規化は、2015年にIoffeとSzegedyによって提案された手法で、ネットワークの中間層の出力をミニバッチ単位で正規化する方法である。学習を安定化させ、勾配消失問題を緩和する効果があることが実用的にわかっている。
ただし、バッチ正規化はミニバッチのサイズに依存するため、特に小さなバッチサイズでの学習では効果が減少することがある。そこで、各データごとに、層ごとに正規化するレイヤー正規化が提案され、Transformerなどのアーキテクチャで広く採用されている。
12.6.2. 残差接続#
勾配消失問題を緩和するための工夫としてよく用いられるのが、残差接続(Residual Connection) と呼ばれる手法である。He et al.によって2015年に提案されたResNet(Residual Network)の中で導入されたもので、深いネットワークの訓練を可能にするための重要な技術である。arXiv:1512.03385
その基本的なアイデアは、ある層の出力に、入力を直接加えることである。
と、言われてもイメージが湧きにくいと思うので、図で説明しよう。
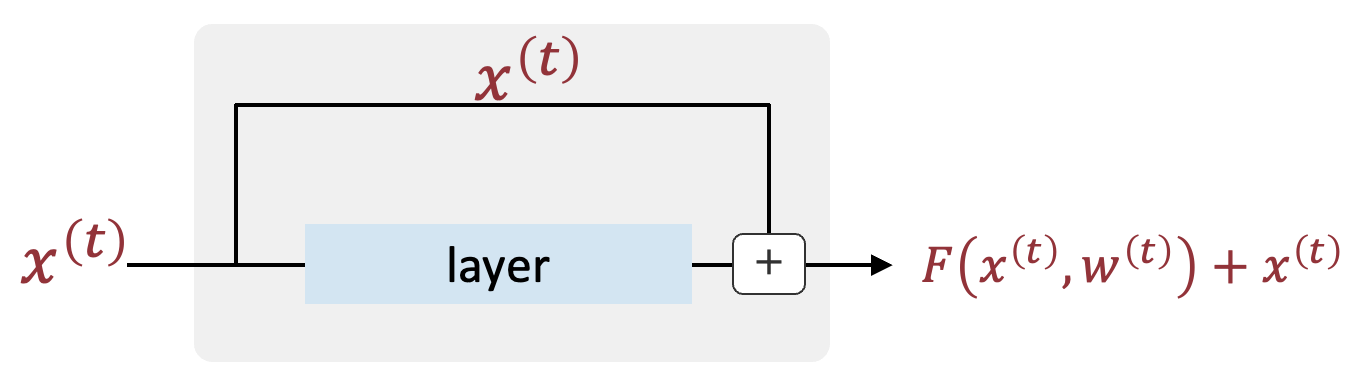
ある層が入力\(x^{(t)}\)を受け取り、通常のネットワークではこの入力に対して何らかの変換を行い、出力\(F(x^{(t)}, w^{(t)})\)を生成する。 残差接続を用いる場合、出力は\(F(x^{(t)}, w^{(t)}) + x^{(t)}\)となる。 このようにすることで、ネットワークは、もし\(F(x^{(t)}, w^{(t)})\)がゼロに近い値を出力する場合でも、入力\(x^{(t)}\)が直接出力に伝わるため、勾配が消失することを防ぐことができる。
もう少し具体的に言うと、与えられたデータの持つ構造に対して、仮に層が冗長であったとしても、その層に恒等写像としての役割を持たせることができるため、ネットワーク全体の表現力を損なうことなく、深いネットワークの訓練が可能になる。
ややいい加減な説明だが、関数の振る舞いを予測する際、その出力値そのものを予測するのではなく、入力(例えば初期値)からの変化量を予測するようなイメージである。例えば、このようなケースは、常微分方程式の数値解法を用いて関数の振る舞いを予測する際などに類似している。 一例として、常微分方程式の数値解法の一つであるオイラー法を考えてみよう。 オイラー法では、ある関数\(f(x(t))\)の微分方程式
を数値的に解くために、次のような更新式を用いる。
この更新式は、現在の状態\(x_t\)に対して、関数\(f(x_t)\)が示す変化量を加える形になっている。 残差接続の場合に、ある層の入力が\(x_t\)で、その層が出力する変化量が\(F(x_t)\)であるとすると、次の層への出力は\(x_{t+1} = x_t + F(x_t)\)となる。
このように、関数の振る舞いを予測する際に、入力からの変化量を予測するアプローチは、残差接続の考え方と類似していると言える。
層の数を無限大に、ステップ幅を無限小に近づけると、ネットワークによる関数の表現は常微分方程式の形になる。 このことを利用したアーキテクチャとして、Neural ODE(Ordinary Differential Equation) と呼ばれるアイデアが提案されている。arXiv:1806.07366
を解いて、ある時刻\(T\)における状態\(x(T)\)を予測する問題に帰着させる。
Neural ODEは、メモリ効率が高く、連続的な時間表現を可能にする(時間間隔が不規則な時系列データとの親和性)などの利点がある一方で、常微分方程式のstiffnessの問題や学習の安定性の問題などが見られるケースもある。