7. ガウス過程(Gaussian Process)#
ガウス過程(Gaussian Process, GP)は、関数の分布を扱うベイズ的なモデルである。主に回帰、ベイズ最適化などで利用される。
特に以下では、関数の回帰を行う関数の分布を推定・生成する方法としての観点から解説する。
理論的な詳細等については下記のガウス過程の名著(通称: GPML)を参照されたい。著者のページから無償でPDFが入手可能である:
"Gaussian Processes for Machine Learning" by Carl Edward Rasmussen and Christopher K. I. Williams
7.1. 概要#
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return 2*np.sin(x) + np.random.normal(0, 3.0, x.shape)
np.random.seed(0)
x = np.linspace(0, 10, 3)
y = f(x)
fig = plt.figure(figsize=(8, 3))
plt.scatter(x, y, color="k")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
plt.close()
今、図のようにデータが観測されているとする。このデータを説明する関数は無数に存在する。 そんな中、単一の関数を選ぶのではなく、「もっともらしい」関数の分布を考えることができれば、より柔軟にデータを説明できると考えられる。
ガウス過程は、このような関数の分布を直接扱うための枠組みの1つである。 背後にある考え方については、以下のとおりである。
任意の近傍二点に対して、その点での関数値は似ている(≒連続)であろう。
"似ている"度合いを非負の値を持つカーネル関数で定量化する。
既知のデータと未知の点での関数値の同時分布を考え、それが多変量ガウス分布に従うと仮定する。
とくに最後の点がガウス過程の名前の由来であると理解してもらってよい。
7.2. ガウス過程の定義#
観測データが \(\mathcal{D} = \{(x_i, y_i)\}_{i=1}^{n}\) で与えられるとする。ここで、\(x_i \in \mathbb{R}\) は説明変数、\(y_i \in \mathbb{R}\) は目的変数である。 説明変数・関数値とも、多次元でも構わないが、ここでは単純化のために1次元としよう。
自分の興味のある\(m\)個の点 \(\mathbf{x}^* \) に対して、関数値 \(\mathbf{y}^*\) を予測したいとする。 このときの\(\mathbf{x}^* = \{x_1^*, x_2^*, \ldots, x_m^*\}\) は、観測データ \(\mathcal{D}\) の説明変数 \(\mathbf{x}_i\) (データ点)とは異なる点であるとし、予測点とでも呼ぶことにする。
そのとき、\(\mathbf{x}, \mathbf{x}^*\) に対する関数値 \(\mathbf{y}, \mathbf{y}^*\) の同時分布が以下のように多変量ガウス分布に従うと仮定する。
平均ベクトルと共分散行列は、データ点と予測点を合わせて\(n+m\)次元のベクトル・行列としてまとめて書いた。 予測点を考えるときは、描画点を多数用意することが多いため、\(m\)は大きな値になることも多い。
ひとたび多次元正規分布の平均ベクトルと共分散行列が与えられれば、条件付き分布もまた多次元正規分布になるため、 以下のように、予測点での関数値の分布を得ることができる。
ここでは、多次元正規分布の条件付き確率分布の計算(3章)を用いた。 この意味するところは、予測点での関数値 \(\mathbf{y}^*\) は、観測データ \(\mathcal{D}\) に基づいて平均と分散が決定される正規分布に従う、ということである。 それぞれの予測点での関数値が分布に従うため、予測点での関数値の不確実性を考慮することができる。
7.3. カーネルとハイパーパラメータ#
カーネル関数 \(k(x, x')\) は、関数の滑らかさや周期性などの事前知識を反映する。代表的なカーネルは以下の通りである:
RBF(ガウス)カーネル:
\[ k(x, x') = \tau \exp\left(-\frac{(x-x')^2}{2l^2}\right) \]ハイパーパラメータ:\(\tau\)(出力のスケール)、\(l\)(長さ尺度, 相関長:correlation lengthとも言う)
Matérnカーネル:
\[ k(x, x') = \tau \frac{2^{1-\nu}}{\Gamma(\nu)} \left( \sqrt{2\nu} \frac{|x-x'|}{l} \right)^\nu K_\nu \left( \sqrt{2\nu} \frac{|x-x'|}{l} \right) \]ここで、\(K_\nu\) は第\(\nu\)種の変形ベッセル関数、\(\Gamma(\nu)\) はガンマ関数である。
ハイパーパラメータ:\(\tau\)(出力のスケール)、\(l\)(長さ尺度)、\(\nu\)(平滑度)
なかでも\(\nu=3/2\)や\(\nu=5/2\)がよく使われる。\(\nu=1/2\)のときは、指数カーネルとも呼ばれ、\(\nu \to \infty\)のときはRBFカーネルとなる。 RBFカーネルは無限回微分可能で非常に滑らかであるのに対し(それはデータが持つ連続性としては過剰な仮定と考えられ)、Matérnカーネルは\(\nu\)によって微分可能な回数が制御される。 実用上においても、RBFカーネルで距離の近いデータ点を取りすぎると、数値的に不安定になることがある。
ハイパーパラメータは、対数尤度最大化などで推定されることが多い。 上の、\(\tau, l\)をまとめて \(\theta = (\tau, l)\) と書くことにして、対数尤度の勾配は以下のように計算される。
また、カーネルが持つべき重要な性質としては、
対称性: \(k(x, x') = k(x', x)\)
正定値性: 任意の異なる点 \(\{x_1, x_2, \ldots, x_n\}\) に対して、対応するカーネル行列 \(K\) が正定値行列であること
非負性: \(k(x, x) \geq 0\) であること
が挙げられる。
問題
逆行列の微分と\(\log |\mathbf{A}|\)の微分の式(線形代数の章を参照)を用いて、上の対数尤度の微分に関する式を導出せよ。
7.4. ノイズの扱い#
ガウス過程では、観測データのノイズを自然に扱うことができる。
ここで、\(\epsilon_i\) は独立同分布に従うガウスノイズであるとする。 このとき、観測データの関数値 \(\mathbf{y}\) の共分散行列は、以下のようにノイズの分散を加えたもの
となる。ここで、\(I\) は単位行列である。このように、ノイズの分散を共分散行列に加えることで、ノイズを考慮した予測が可能となる。
一点注意すべきは、ノイズの分散 \(\sigma_n^2\) は、カーネルのハイパーパラメータとして推定されることが多いことである。
既存のGPyなどのライブラリでは、データを与えた際に、ノイズの分散を含むハイパーパラメータを対数尤度最大化で推定する機能が備わっている。
データは(多くの場合)標準化されていることが多いため、ノイズの分散は1よりもかなり小さい値になることが期待されるが、対数尤度最大化の結果、非常に大きな値になることがある。
この場合、データが本来持つ不定性を過大評価してしまうため、予測が過度に平滑化されてしまうことがある。
筆者の経験上、このあたりの問題を適切に理解した応用がなされていないものも多く散見するため、注意が必要である。
実装の背後にある理論や、データのドメイン知識が必要となる好例である。
7.5. 実装#
Pythonでは、GPyやscikit-learnなどのライブラリがガウス過程の実装を提供している。
以下では、自前でMatérnカーネル(\(\nu=5/2\))を用いたガウス過程を実装してみる。
とりあえず、ハイパーパラメータを固定して、予測点での関数値の分布を計算してみよう。
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import copy
from scipy import special
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
## ガウス過程のカーネル(共分散行列)の設計
def Mat52(Thetas,r):
tau,sigma = Thetas
thetar = r * np.sqrt(5.0)/sigma
return tau * (1.0 + thetar + (thetar**2) /3.0) * np.exp(-thetar)
def KernelMat(Thetas,xt,xp):
lt = len(xt); lp=len(xp)
Ktt = np.zeros((lt,lt)); Kpt = np.zeros((lp,lt)); Kpp = np.zeros((lp,lp))
for j in range(lt):
for i in range(j,lt):
r = abs(xt[i]-xt[j])
tmp = Mat52(Thetas,r)
Ktt[i,j] = tmp; Ktt[j,i] = tmp
for i in range(lp):
r= abs(xp[i]-xt[j])
Kpt[i,j] = Mat52(Thetas,r)
for j in range(lp):
for i in range(j,lp):
r= abs(xp[i]-xp[j])
tmp = Mat52(Thetas,r)
Kpp[i,j] = tmp; Kpp[j,i] = tmp
return Ktt,Kpt,Kpp
## 事後共分散行列の計算
def calcSj(cLinv,Kpt,Kpp,yt,mu_yt,mu_yp):
tKtp= np.dot(cLinv,Kpt.T)
return mu_yp + np.dot(Kpt,np.dot(cLinv.T,np.dot(cLinv,yt-mu_yt))), Kpp - np.dot(tKtp.T,tKtp)
## Cholesky分解
def Mchole(tmpA,ln) :
cLL = np.linalg.cholesky(tmpA)
logLii=0.0
for i in range(ln):
logLii += np.log(cLL[i,i])
return np.linalg.inv(cLL), 2.0*logLii
## データ点&予測点の設定
np.random.seed(0)
x = np.linspace(2, 8, 10)
y = f(x)
y = (np.array(y) - np.mean(y)) / np.std(y) # 標準化
xp = np.linspace(0, 10, 200)
## ガウス過程の実装
for Thetas in [[1.0, 0.5, 1e-1], [1.0, 1.0, 1e-2]]:
lt=len(x); lp=len(xp)
Ktt,Kpt,Kpp = KernelMat(Thetas[:2], x, xp)
mu_yt= np.mean(y)*np.ones(lt)
mu_yp= np.mean(y)*np.ones(lp)
cLinv,logdetK = Mchole(Ktt,lt)
mujoint,Sjoint = calcSj(cLinv, Kpt, Kpp, y, mu_yt, mu_yp)
sigmaj=[ Sjoint[j][j] for j in range(lp)]
ysamples = [np.random.multivariate_normal(mujoint,Sjoint) for i in range(10)]
fig = plt.figure(figsize=(8, 3))
plt.scatter(x, y, color="k", label="data")
plt.plot(xp, mujoint, color="b", label="mean")
plt.fill_between(xp, mujoint-1.96*np.sqrt(sigmaj), mujoint+1.96*np.sqrt(sigmaj), color="b", alpha=0.2, label="95% CI")
for ys in ysamples:
plt.plot(xp, ys, alpha=0.3, linestyle="--")
plt.xlabel("x")
plt.ylabel("y")
plt.title(f"GP regression with Mat52 kernel (tau={Thetas[0]:6.2f}, sigma={Thetas[1]})")
plt.legend()
plt.show()
plt.close()
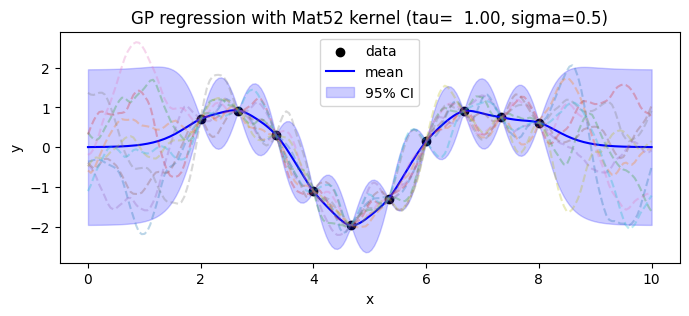
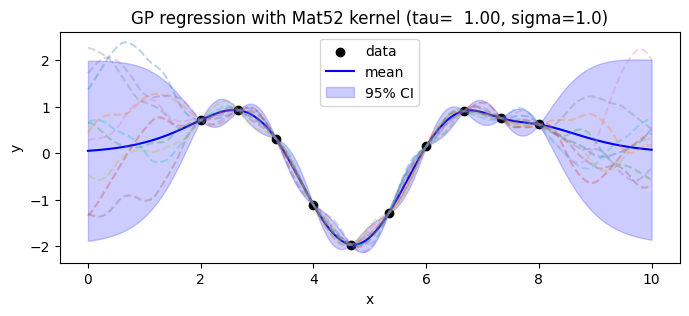
青線が、事後分布の平均、青色のバンドが、95%信頼区間を示している。破線で示したのは、事後確率から得られたサンプルである。
\(d\)個のデータ点と相関した\(m\)個の予測点を同時にサンプルすれば、各点で独立した値ではなく、連続的な関数のサンプルを得ることができる。
また\(K(\mathbf{x}, \mathbf{x})\)の逆行列を計算する際に、数値的に不安定になる。上の実装では、コレスキー分解を用いた。
ここで、\(L\)は下三角行列である。これを用いると、逆行列の計算は以下のように安定に行うことができる。
念の為、同じハイパーパラメータで、GPyのガウス過程の実装と比較してみよう。
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import GPy
# テスト関数(自作コードで使っていた f(x) と同じものを定義してください)
def f(x):
return np.sin(x) + 0.5 * np.cos(2*x)
# データ点&予測点の設定
np.random.seed(0)
x = np.linspace(2, 8, 10)
y = f(x)
y = (np.array(y) - np.mean(y)) / np.std(y) # 標準化
xp = np.linspace(0, 10, 200)
# GPyでのガウス過程の実装
Thetas = [1.0, 1.0, 1.e-2]
tau, sigma, noise_var = Thetas
# カーネル: tau * Matern52(length_scale=sigma)
kernel = GPy.kern.Matern52(input_dim=1, variance=tau, lengthscale=sigma)
gp = GPy.models.GPRegression(x.reshape(-1,1), y.reshape(-1,1), kernel, noise_var=0)
# 予測
y2, e2 = gp.predict(xp.reshape(-1,1))
mujoint_ = y2.reshape(-1,)
stdj_ = np.sqrt( e2.reshape(-1,) )
# 可視化
plt.figure(figsize=(8,3))
plt.scatter(x, y, color="k", label="data")
plt.plot(xp, mujoint_, color="b", label="mean (my code)")
plt.fill_between(xp, mujoint_-1.96*np.sqrt(sigmaj), mujoint_+1.96*np.sqrt(sigmaj), color="b", alpha=0.2, label="95% CI (my code)")
plt.plot(xp, mujoint_, color="g", label="mean", linestyle="--")
plt.fill_between(xp, mujoint_-1.96*stdj_, mujoint_+1.96*stdj_, color="g", alpha=0.2, label="95% CI")
#for ys in ysamples.T:
# plt.plot(xp, ys, "--", alpha=0.3)
plt.xlabel("x")
plt.ylabel("y")
plt.title(f"sklearn GP (Mat52 kernel, tau={tau:6.2f}, sigma={sigma:6.2f})")
plt.legend()
plt.show()
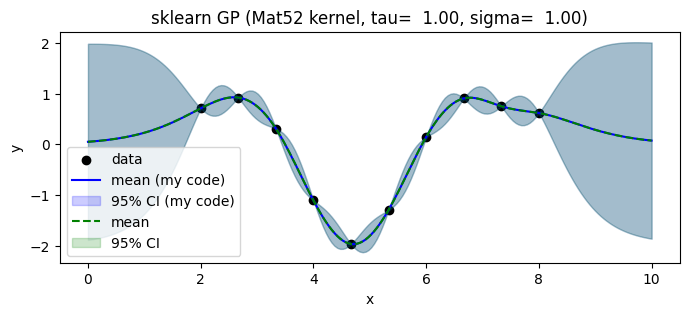
両者がピッタリ重なっている事がわかる。ただし、GPyやscikit-learnなどのライブラリでは、データの分散や予測分散を別々にカスタマイズするのがやや面倒だったりもする。
7.6. \(\clubsuit\) 正規乱数の生成について#
余談になるが、正規分布に従う乱数の生成をどのように行えばよいだろうか?
もちろんnumpyやscipyなどのライブラリを使えば簡単に生成できるが、
どのように生成されているのか紹介しておこう。
簡単のため1次元の場合を考える。標準正規分布に従う乱数\(z\)を生成する方法の一つに、Box-Muller法がある。
Box-Muller法では、\(U_1, U_2\)を\([0,1)\)の一様分布に従う独立な乱数とするとき、以下の変換によって得られる\(Z_0, Z_1\)が標準正規分布に従うことを利用する。
この方法は、極座標変換を用いて、2次元の標準正規分布に従う乱数を生成し、それを1次元に分解している。 半径部分が指数分布に、角度部分が一様分布に従うことを利用している。
コードで確かめてみよう。一様乱数を2つ生成し、Box-Muller法で標準正規乱数を生成し、散布図とヒストグラムを描画してみた。
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def BoxMuller(u1, u2):
z0 = np.sqrt(-2.0 * np.log(u1)) * np.cos(2.0 * np.pi * u2)
z1 = np.sqrt(-2.0 * np.log(u1)) * np.sin(2.0 * np.pi * u2)
return z0, z1
num_samples = 10**4
u1u2s = np.random.uniform(0, 1, (num_samples, 2))
samples = BoxMuller(u1u2s[:, 0], u1u2s[:, 1])
h = sns.jointplot(x=samples[0], y=samples[1],
color='#e2c6ff', alpha=0.3,
height=4)
h.set_axis_labels('z0', 'z1')
plt.show()
続いて、多次元正規分布に従う乱数を生成する方法についても紹介しよう。
こちらも、np.random.multivariate_normalなどの実装があるので、実用上はそれを使えばよいが、詳細な実現方法の一例を知っておくと便利である。
多次元正規分布の乱数生成は、共分散行列 \(\Sigma\) のコレスキー分解を用いればよい。
このとき、標準正規分布に従う乱数ベクトル \(\mathbf{z} \sim \mathcal{N}(0, I)\) に対して、変換
によって、\(\mathbf{y} \sim \mathcal{N}(\boldsymbol{\mu}, \Sigma)\) に従う乱数ベクトルを生成できる。
余談ついでに昔話をすると、Numpyの多次元正規分布は(少なくとも筆者が大学院生の頃は)何も考えずに使うとthread-unsafe、つまりマルチスレッド環境で使うと同様の乱数が生成されてしまう仕様であった。そのことに気がついたのは、粒子フィルタ(particle filter)と呼ばれる複数のworkerでサンプリングを行う、マルコフ連鎖モンテカルロ法の逐次バージョン的なアルゴリズムを実装していたときで、独立なはずのworkerが同じ乱択を繰り返していることに気が付いた。
Numpy 2.0になってからは、RNG(乱数生成器)周りでの改良が行われたようだが、やはり実際の乱数生成の結果を都度確認する癖はつけておいた方がよいだろう。
7.7. ベイズ最適化#
ガウス過程は、ベイズ最適化の核としても広く使われる。 関数の振る舞いをガウス過程でモデル化し、その不確実性を考慮しながら最適化を進めていく。
とくに、1回の観測(や数値実験など)にコストがかかり、勾配が利用できないような関数の最適化に有効である。 また、探索と活用のトレードオフを考慮しながら、効率的に最適解に近づくことができることも多く 機械学習のハイパーパラメータチューニングなどにも利用される。 探索というのは「井の中の蛙状態が怖いので、未知の領域を探索してみよう」というイメージで、 活用というのは「今までの経験から良さそうなところを掘り下げてみよう」というイメージである。
例えば今の関数の振る舞いを、パラメータ空間に対するコスト関数だと考え、その最小化や最大化を目指すとする。 すでに得られているデータ点をもとに、次に評価する点を獲得関数で決定する。 言い換えると、情報利得が高そうかつ、良さそうな点を次に評価するための、戦略を立てるための枠組みとも言える。
以下に、実装例を示す。 なお、獲得関数には、期待改善量(Expected Improvement, EI)を用いている。
ここで\(\Phi, \phi\)はそれぞれ標準正規分布の累積分布関数と確率密度関数である。この他にも
PI(Probability of Improvement): 現状の最適値よりもさらに良くなる確率を計算して次点を選ぶ方法
UCB(Upper Confidence Bound)/LCB(Lower Confidence Bound): ガウス過程の予測平均と分散を組み合わせて次点を選ぶ方法
Show code cell source
#使うライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
import copy
from scipy import special
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
## データの生成用関数
def f(x):
return np.sin(x) + 0.2 * x
## 獲得関数を計算, 次点の計算点を決める
def calcEI(xp,mujoint,sigmaj,xbest,ybest):
EIs = [ (mujoint[i]-ybest) * Phi((mujoint[i]-ybest)/sigmaj[i]) +
sigmaj[i]* np.exp(-0.5* ((mujoint[i]-ybest)/sigmaj[i])**2) for i in range(len(xp))]
xnew,ynew,ind=xybest(xp,EIs)
ynew= np.sin(xnew) + 0.2*xnew #+ 0.01 * (0.5-np.random.rand())
return xnew,ynew,EIs,ind
def Phi(z):
return 0.5 * special.erfc(-(z/(2**0.5)) )
def xybest(xt,yt):
ind = np.argmax(yt)
return xt[ind],yt[ind],ind
def plotGP(nxt,nyt,nxp,xp,ytrue,mujoint,sigmaj,ysamples,EIs):
fig = plt.figure(figsize=(10, 4))
axT = fig.add_subplot(121)
axB = fig.add_subplot(122)
axT.set_xlabel("x"); axT.set_ylabel("y")
axB.set_xlabel("x"); axB.set_ylabel("Acquisition function")
axT.set_xlim(-2.0,12); axT.set_ylim(-2.0,5.0)
axB.set_xlim(-2.0,12)
axT.scatter(nxt,nyt,marker="o",color="black",label="Data")
for i in range(len(ysamples)):
axT.plot(nxp,ysamples[i],alpha=0.1)
axT.plot(nxp,mujoint,label="GP mean",linestyle="dashed",color="blue")
axB.plot(nxp,EIs,color="green")
axB.set_yticklabels([])
axT.fill_between(nxp,mujoint-sigmaj,mujoint+sigmaj,color="blue", alpha=0.3)
axT.plot(xp,ytrue,color="red",label="True",linestyle="dotted")
axT.legend(loc="upper right")
plt.show()
plt.close()
Thetas=[2.0,2.0]
oxt = np.array([ 0.0 + 1.02*i for i in range(11)])
xp = []
for tmp in np.arange(-2.0,12.0, 5.e-2):
if (tmp in oxt)==False:
xp += [ tmp ]
xp = np.array(xp)
oyt = f(oxt)
ytrue = f(xp)
SVs=[]
xt =[oxt[2],oxt[6]]; yt =[oyt[2],oyt[6]]
nxp = list(copy.copy(xp))
nxt = copy.copy(xt)
nyt = copy.copy(yt)
n_iter = 10 ## 探索回数の上限
xopt = 6; yopt = -1.e+30
## お絵かき
fig = plt.figure(figsize=(10,4))
axT = fig.add_subplot(121)
axB = fig.add_subplot(122)
scatter = axT.scatter(nxt, nyt, s=10, alpha=0.5)
title = axB.set_title("")
def plotGP(iter):
nxt, nyt, nxp, mujoint, sigmaj, ysamples, EIs, xnew = snapshots[iter]
axT.clear()
axB.clear()
axT.set_xlabel("x"); axT.set_ylabel("y")
axB.set_xlabel("x"); axB.set_ylabel("Acquisition function")
axT.set_xlim(-2.0,12); axT.set_ylim(-2.0,5.0)
axB.set_xlim(-2.0,12)
axT.scatter(nxt,nyt,marker="o",color="black",label="Data")
axT.vlines(xnew, -2.0, 5.0, lw=3, colors="gray", linestyles="dotted", label="Next point")
axB.vlines(xnew, 0.0, max(EIs), lw=3, colors="gray", linestyles="dotted")
for i in range(len(ysamples)):
axT.plot(nxp,ysamples[i],alpha=0.1)
axT.plot(nxp,mujoint,label="GP mean",linestyle="dashed",color="blue")
axB.plot(nxp,EIs,color="green")
axB.set_yticklabels([])
axT.fill_between(nxp,mujoint-sigmaj,mujoint+sigmaj,color="blue", alpha=0.3)
axT.plot(xp,ytrue,color="red",label="True",linestyle="dotted")
axT.legend(loc="upper right")
snapshots = [ ]
for iter in range(n_iter):
lt=len(nxt); lp=len(nxp)
Ktt,Kpt,Kpp = KernelMat(Thetas,nxt,nxp)
mu_yt= np.zeros(lt)
mu_yp= np.zeros(lp)
cLinv,logdetK = Mchole(Ktt,lt)
mujoint,Sjoint = calcSj(cLinv,Kpt,Kpp,nyt,mu_yt,mu_yp)
sigmaj=[ Sjoint[j][j] for j in range(lp)]
ysamples = [np.random.multivariate_normal(mujoint,Sjoint) for i in range(10)]
SVs += [ [ mujoint, sigmaj] ]
xbest,ybest,ind= xybest(nxt,nyt)
xnew,ynew,EIs,ind = calcEI(nxp,mujoint,sigmaj,xbest,ybest)
snapshots += [ [nxt.copy(), nyt.copy(), nxp.copy(),
mujoint.copy(), sigmaj.copy(), ysamples.copy(), EIs.copy(),
xnew] ]
# 次点のための操作 (データ点の追加と候補の削除)
nxt += [ xnew ]; nyt += [ ynew ]
nxp.pop(ind)
if ynew > yopt:
xopt= xnew; yopt = ynew
anim = FuncAnimation(fig, plotGP, frames=n_iter, interval=1000)
plt.close(fig)
display(HTML(anim.to_jshtml()))
今は単なる一次元の例を示したが、多次元にも拡張可能である。 最後に、ベイズ最適化を用いた各種のアプリケーションについて例示しておく。
ハイパーパラメータチューニング: 機械学習モデルのハイパーパラメータを最適化するために使用される。例えば、ニューラルネットワークの学習率や正則化パラメータの最適化など、人が手動で試行錯誤する作業を自動化できる。
材料科学: 新しい材料・化合物の特性(バンドギャップ、強度、磁化率など)の探索のためのスクリーニングに利用される。実験や数値シミュレーションなどのコストが高い場合に有用となる。
共通するのは、1回のデータの観測・評価・取得にコストがかかる場合であり、そのような場合に、効率的に最適解に近づくための手法としてベイズ最適化が有効であるということである。
獲得関数の設計やカーネルの選択など、応用に応じた工夫が必要となる場合も多いが、比較的容易に実装できるため、試してみる価値は大いにある。