![]()
ベイズ最適化による実験計画法#
以下では、ベイズ最適化を用いた実験計画法を見てみよう。
数学的部分やコードの詳細よりも「なんとなくこのあたりを探索しようかな」といった
人間の経験に依る部分を客観的な方法で置き換えた実験計画の方法論の強力さを感じることが目的なので難しいところはスキップしても構わない。
ガウス過程の基本や詳細は補足ノートに譲る.
#使うライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
import copy
from scipy import special
## データの生成用関数
def f(x):
return np.sin(x) + 0.2 * x
## ガウス過程のカーネル(共分散行列)の設計
def Mat52(Thetas,r):
tau,sigma = Thetas
thetar = r * np.sqrt(5.0)/sigma
return tau * (1.0 + thetar + (thetar**2) /3.0) * np.exp(-thetar)
def KernelMat(Thetas,xt,xp):
lt = len(xt); lp=len(xp)
Ktt = np.zeros((lt,lt)); Kpt = np.zeros((lp,lt)); Kpp = np.zeros((lp,lp))
for j in range(lt):
for i in range(j,lt):
r = abs(xt[i]-xt[j])
tmp = Mat52(Thetas,r)
Ktt[i,j] = tmp; Ktt[j,i] = tmp
for i in range(lp):
r= abs(xp[i]-xt[j])
Kpt[i,j] = Mat52(Thetas,r)
for j in range(lp):
for i in range(j,lp):
r= abs(xp[i]-xp[j])
tmp = Mat52(Thetas,r)
Kpp[i,j] = tmp; Kpp[j,i] = tmp
return Ktt,Kpt,Kpp
## 事後共分散行列の計算
def calcSj(cLinv,Kpt,Kpp,yt,mu_yt,mu_yp):
tKtp= np.dot(cLinv,Kpt.T)
return mu_yp + np.dot(Kpt,np.dot(cLinv.T,np.dot(cLinv,yt-mu_yt))), Kpp - np.dot(tKtp.T,tKtp)
## Cholesky分解
def Mchole(tmpA,ln) :
cLL = np.linalg.cholesky(tmpA)
logLii=0.0
for i in range(ln):
logLii += np.log(cLL[i,i])
return np.linalg.inv(cLL), 2.0*logLii
## 獲得関数を計算, 次点の計算点を決める
def calcEI(xp,mujoint,sigmaj,xbest,ybest):
EIs = [ (mujoint[i]-ybest) * Phi((mujoint[i]-ybest)/sigmaj[i]) +
sigmaj[i]* np.exp(-0.5* ((mujoint[i]-ybest)/sigmaj[i])**2) for i in range(len(xp))]
xnew,ynew,ind=xybest(xp,EIs)
ynew= np.sin(xnew) + 0.2*xnew #+ 0.01 * (0.5-np.random.rand())
return xnew,ynew,EIs,ind
def Phi(z):
return 0.5 * special.erfc(-(z/(2**0.5)) )
def xybest(xt,yt):
ind = np.argmax(yt)
return xt[ind],yt[ind],ind
## お絵かき
def plotGP0(xt,yt,xp,ytrue):
fig = plt.figure(figsize=(8,4))
axT = fig.add_subplot(1,1,1)
axT.set_xlabel("x"); axT.set_ylabel("y")
axT.set_xlim(-2.0,12); axT.set_ylim(-2.0,5.0)
axT.scatter(xt,yt,marker="o",color="black",label="Data")
axT.plot(xp,ytrue,color="red",label="True",linestyle="dotted")
axT.legend(loc="upper right")
plt.show()
#plt.savefig("BayesOpt_initial.pdf",bbox_inches="tight", pad_inches=0.1)
plt.close()
def plotGP(nxt,nyt,nxp,xp,ytrue,mujoint,sigmaj,ysamples,EIs):
fig = plt.figure(figsize=(16,4))
axT = fig.add_subplot(121)
axB = fig.add_subplot(122)
axT.set_xlabel("x"); axT.set_ylabel("y")
axB.set_xlabel("x"); axB.set_ylabel("Acquisition function")
axT.set_xlim(-2.0,12); axT.set_ylim(-2.0,5.0)
axB.set_xlim(-2.0,12)
axT.scatter(nxt,nyt,marker="o",color="black",label="Data")
for i in range(len(ysamples)):
axT.plot(nxp,ysamples[i],alpha=0.1)
axT.plot(nxp,mujoint,label="GP mean",linestyle="dashed",color="blue")
axB.plot(nxp,EIs,color="green")
axB.set_yticklabels([])
axT.fill_between(nxp,mujoint-sigmaj,mujoint+sigmaj,color="blue", alpha=0.3)
axT.plot(xp,ytrue,color="red",label="True",linestyle="dotted")
axT.legend(loc="upper right")
plt.show()
plt.close()
Thetas=[2.0,2.0]
oxt = np.array([ 0.0 + 1.02*i for i in range(11)])
xp = []
for tmp in np.arange(-2.0,12.0, 5.e-2):
if (tmp in oxt)==False:
xp += [ tmp ]
xp = np.array(xp)
oyt = f(oxt)
ytrue = f(xp)
SVs=[]
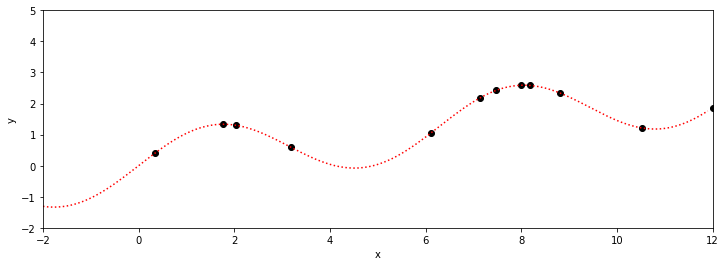
xt =[oxt[2],oxt[6]]; yt =[oyt[2],oyt[6]]
plotGP0(xt,yt,xp,ytrue)
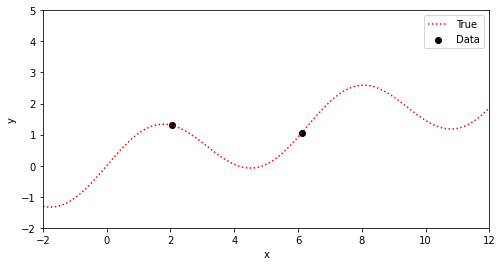
一般には真の関数(赤色)は分からないので、勾配も計算できない。
数値的に勾配を計算するには、各点で微小にxをずらした場合の観測が必要、さらに、学習率を変えながら適当な値を探索するというのは、1回のデータの観測(測定,取得,計算, etc.)コストが高い場合はあまり良い方策ではない。(“学習率”については最適化の章を参照)
仮に勾配の計算ができたとしても、このデータの様に背後にある真の関数が多峰的(multimodal)な場合、勾配のみに基づく単純な最適化手法では局所解に停留する危険もある。
そこでベイズ最適化を用いることで大局的な探索と局所的な探索をうまくトレードオフしながら最適値を探索する、ということを以下でデモンストレーションする。
Thetas=[2.0,2.0]
nxp = list(copy.copy(xp))
nxt = copy.copy(xt)
nyt = copy.copy(yt)
n_iter = 10 ## 探索回数の上限
xopt = 6; yopt = -1.e+30
SVs=[]
plot = True
#plot = False
for iter in range(n_iter):
lt=len(nxt); lp=len(nxp)
Ktt,Kpt,Kpp = KernelMat(Thetas,nxt,nxp)
mu_yt= np.zeros(lt)
mu_yp= np.zeros(lp)
cLinv,logdetK = Mchole(Ktt,lt)
mujoint,Sjoint = calcSj(cLinv,Kpt,Kpp,nyt,mu_yt,mu_yp)
sigmaj=[ Sjoint[j][j] for j in range(lp)]
ysamples = [np.random.multivariate_normal(mujoint,Sjoint) for i in range(10)]
SVs += [ [ mujoint, sigmaj] ]
xbest,ybest,ind= xybest(nxt,nyt)
xnew,ynew,EIs,ind = calcEI(nxp,mujoint,sigmaj,xbest,ybest)
if plot :
plotGP(nxt,nyt,nxp,xp,ytrue,mujoint,sigmaj,ysamples,EIs)
nxt += [ xnew ]; nyt += [ ynew ]
nxp.pop(ind)
if ynew > yopt:
xopt= xnew; yopt = ynew
print(iter, xopt, yopt)
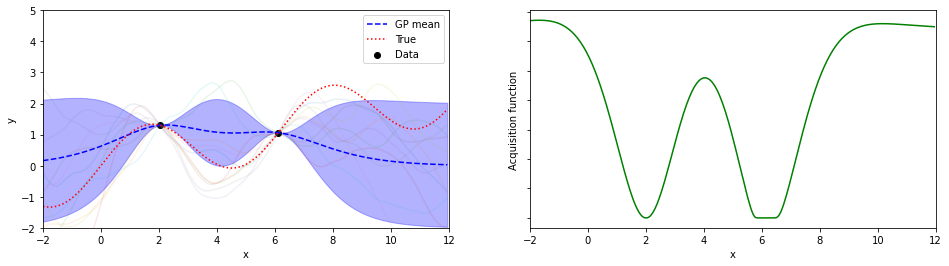
0 -1.6999999999999997 -1.3316648104524687
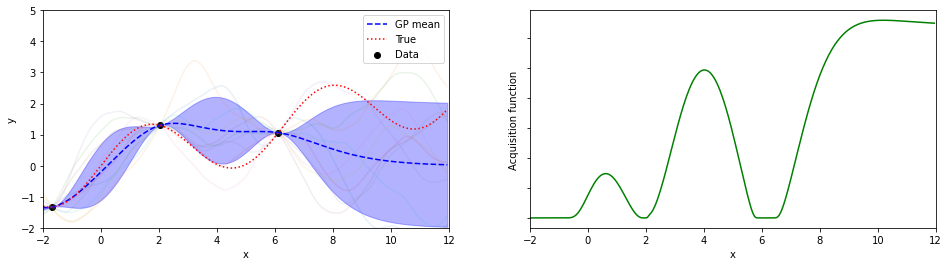
1 10.20000000000001 1.3401253124064523
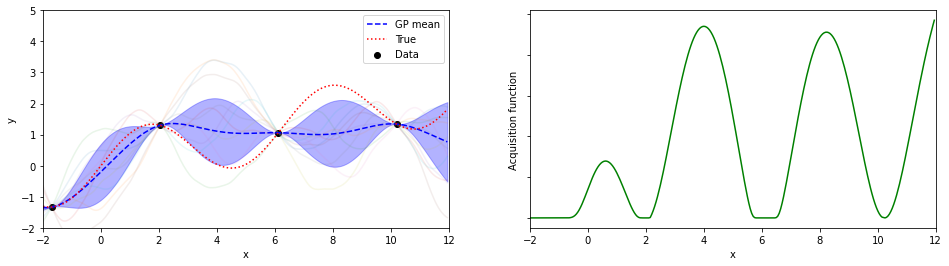
2 11.950000000000012 1.8119225385829674
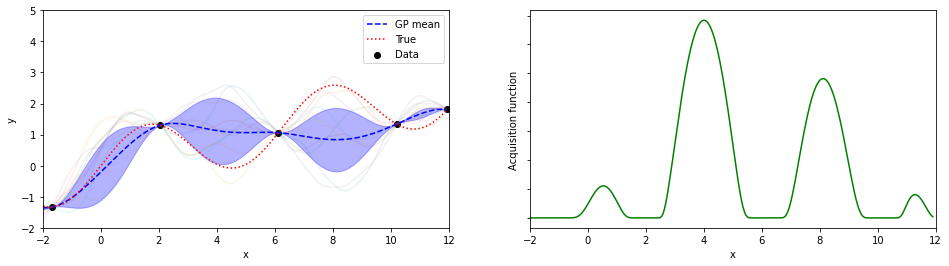
3 11.950000000000012 1.8119225385829674
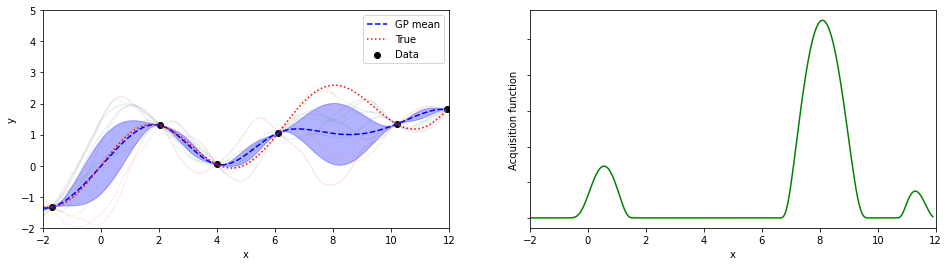
4 8.100000000000009 2.589889810845086
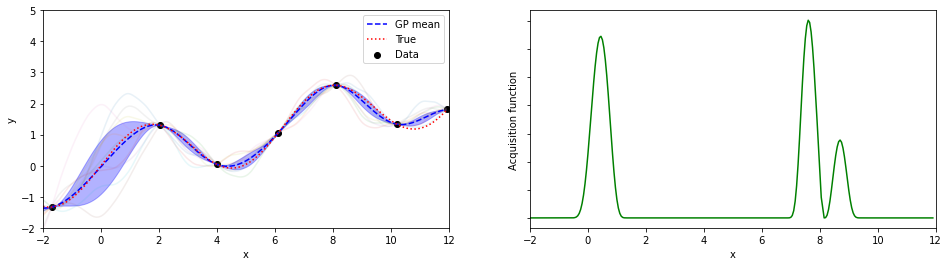
5 8.100000000000009 2.589889810845086
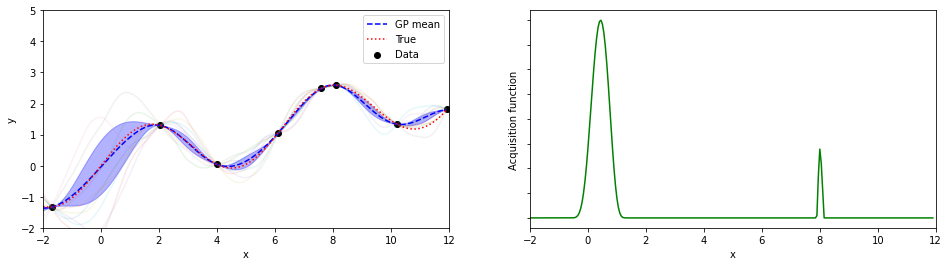
6 8.100000000000009 2.589889810845086
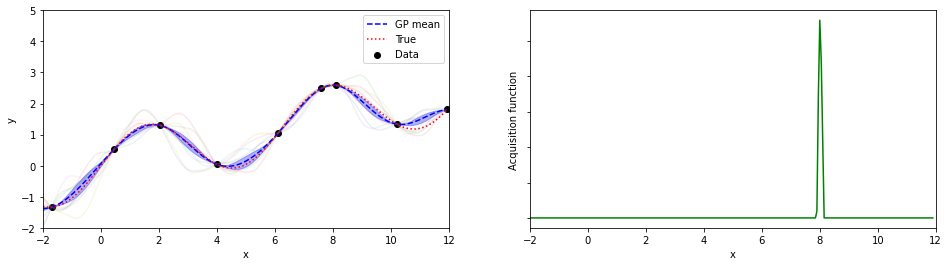
7 8.100000000000009 2.589889810845086
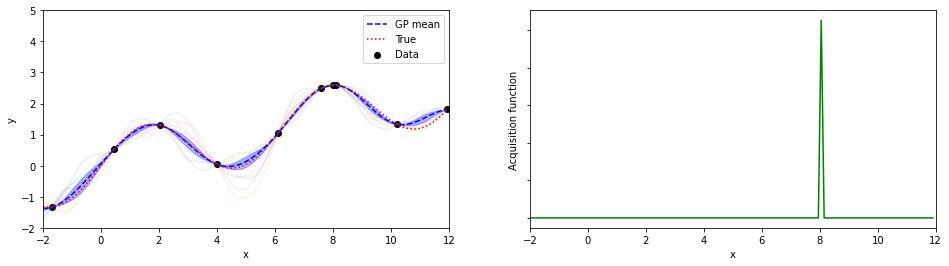
8 8.05000000000001 2.5908498356204
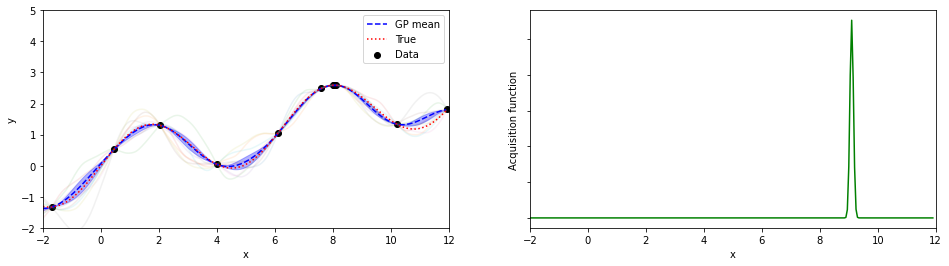
9 8.05000000000001 2.5908498356204
探索点が増えるにつれて、効率的に最適解が探索出来ている(っぽい)。
8回目の探索でx=8.05が探索されていて、真の解8.055…にそこそこ近いものが得られている。
(実装の都合上、0.05刻みでしか点を打ってないことに注意)
同じデータで、勾配法による最適化もやってみる。
import numpy as np
def f(x):
return np.sin(x) + 0.2 * x
def derf(x):
return np.cos(x) + 0.2
xexact = 8.055339554764814
x = 6
xopt = x; yopt=f(x)
tol = 1.e-2
eta = 1.e-1
itnum = 10**4
for i in range(itnum):
x += eta * derf(x)
y = f(x)
if y > yopt:
xopt = x
yopt = y
if abs(xexact-xopt) < tol :
break
print("探索回数",i, "最適解(x,y)=",xopt,yopt)
探索回数 53 最適解(x,y)= 8.045494422941772 2.590816292488816
\(\eta\)を適切に選べれば、より少ない探索回数でより正確な解が求まるが、そんなことができたら苦労はしない…。
また今の場合、勾配は式から計算したが、実際には差分をとって微分を近似することになるため探索回数は少なくとも2倍-3倍程度必要になる。
言及しなかった重要な事項
カーネル関数の選択と依存性
ハイパーパラメータの最適化 or サンプリング
獲得関数の定義・選択と依存性
数値計算(とくにガウス過程の部分)のTips
備忘録: ライブラリの出力に関して#
Thetas=[1.0,1.0]
nxp = np.linspace(-2,12,10)
nxt = copy.copy(xt);nyt = copy.copy(yt)
n_iter = 10 ## 探索回数の上限
xopt = 6; yopt = -1.e+30
SVs=[]
plot = False
lt=len(nxt); lp=len(nxp)
Ktt,Kpt,Kpp = KernelMat(Thetas,nxt,nxp)
mu_yt= np.zeros(lt)
mu_yp= np.zeros(lp)
cLinv,logdetK = Mchole(Ktt,lt)
mujoint,Sjoint = calcSj(cLinv,Kpt,Kpp,nyt,mu_yt,mu_yp)
sigmaj=[ np.sqrt(Sjoint[j][j]) for j in range(lp)]
print("train", nxt,nyt)
print("xp", nxp)
print("My muj ", mujoint)
print("sigmaj", sigmaj)
train [2.04, 6.12] [1.2999286509533796, 1.061537984784846]
xp [-2. -0.44444444 1.11111111 2.66666667 4.22222222 5.77777778
7.33333333 8.88888889 10.44444444 12. ]
My muj [5.75795234e-03 8.44113811e-02 7.33727607e-01 9.88413223e-01
3.06567459e-01 9.73202438e-01 4.32586459e-01 4.31993679e-02
2.79241473e-03 1.47812049e-04]
sigmaj [0.9999901297449515, 0.9978771506830272, 0.8245848824042269, 0.6584175494971636, 0.9813489474851831, 0.4100810951379304, 0.9125129281442049, 0.9991642392577667, 0.9999965079965879, 0.9999999902138795]
from sklearn.gaussian_process import kernels as sk_kern
import sklearn.gaussian_process as skGP
# sklearn GP
nxp = np.linspace(-2,12,10)
nxt = np.array(copy.copy(xt))
nyt = np.array(copy.copy(yt))
kern = sk_kern.Matern(length_scale=1.0, length_scale_bounds=(1.0,1.0), nu=2.5)
sGP = skGP.GaussianProcessRegressor(
kernel=kern,
alpha=1e-15,
optimizer="fmin_l_bfgs_b",
n_restarts_optimizer=0)
sGP.fit(nxt.reshape(-1, 1), nyt)
print("sGP.kernel_", sGP.kernel_)
pred_mean, pred_std= sGP.predict(nxp.reshape(-1,1), return_std=True)
print(pred_mean.reshape(-1,))
print(pred_std)
sGP.kernel_ Matern(length_scale=1, nu=2.5)
[-5.75795234e-03 -8.44113811e-02 -7.33727607e-01 -9.88413223e-01
-3.06567459e-01 -9.73202438e-01 -4.32586459e-01 -4.31993679e-02
-2.79241473e-03 -1.47812049e-04]
[0.99999013 0.99787715 0.82458488 0.65841755 0.98134895 0.4100811
0.91251293 0.99916424 0.99999651 0.99999999]
!pip install GPy
Collecting GPy
Downloading GPy-1.10.0.tar.gz (959 kB)
|████████████████████████████████| 959 kB 4.3 MB/s
?25hRequirement already satisfied: numpy>=1.7 in /usr/local/lib/python3.7/dist-packages (from GPy) (1.19.5)
Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from GPy) (1.15.0)
Collecting paramz>=0.9.0
Downloading paramz-0.9.5.tar.gz (71 kB)
|████████████████████████████████| 71 kB 8.9 MB/s
?25hRequirement already satisfied: cython>=0.29 in /usr/local/lib/python3.7/dist-packages (from GPy) (0.29.26)
Requirement already satisfied: scipy>=1.3.0 in /usr/local/lib/python3.7/dist-packages (from GPy) (1.4.1)
Requirement already satisfied: decorator>=4.0.10 in /usr/local/lib/python3.7/dist-packages (from paramz>=0.9.0->GPy) (4.4.2)
Building wheels for collected packages: GPy, paramz
Building wheel for GPy (setup.py) ... ?25l?25hdone
Created wheel for GPy: filename=GPy-1.10.0-cp37-cp37m-linux_x86_64.whl size=2565113 sha256=d3f5efe34d8d7393bde5e956d9d3aaa15a46e98c97fa52624778f8952750d950
Stored in directory: /root/.cache/pip/wheels/f7/18/28/dd1ce0192a81b71a3b086fd952511d088b21e8359ea496860a
Building wheel for paramz (setup.py) ... ?25l?25hdone
Created wheel for paramz: filename=paramz-0.9.5-py3-none-any.whl size=102566 sha256=7642fed4b69b594975067d330d9293b5502326530e2cb3589eb51d00117e7bb7
Stored in directory: /root/.cache/pip/wheels/c8/95/f5/ce28482da28162e6028c4b3a32c41d147395825b3cd62bc810
Successfully built GPy paramz
Installing collected packages: paramz, GPy
Successfully installed GPy-1.10.0 paramz-0.9.5
import GPy
nxp = np.linspace(-2,12,10).reshape(-1,1)
nxt = np.array(copy.copy(xt)).reshape(-1,1)
nyt = np.array(copy.copy(yt)).reshape(-1,1)
kern = GPy.kern.Matern52(input_dim=1,variance=1.0,lengthscale=1.0)
model = GPy.models.GPRegression(X=nxt, Y=nyt, kernel=kern,normalizer=None)
print(model)
pred_mean, pred_var = model.predict(nxp)
print("results(default) ", pred_mean.reshape(-1,), "\n",pred_var.reshape(-1,))
model = GPy.models.GPRegression(X=nxt, Y=nyt, kernel=kern,noise_var=1.e-15, normalizer=None)
pred_mean, pred_var = model.predict(nxp)
print(model)
print("results(noise_var~0)", pred_mean.reshape(-1,), "\n",pred_var.reshape(-1,))
Name : GP regression
Objective : 3.2337691135149766
Number of Parameters : 3
Number of Optimization Parameters : 3
Updates : True
Parameters:
GP_regression. | value | constraints | priors
Mat52.variance | 1.0 | +ve |
Mat52.lengthscale | 1.0 | +ve |
Gaussian_noise.variance | 1.0 | +ve |
results(default) [-2.88381322e-03 -4.22766071e-02 -3.67480418e-01 -4.95042500e-01
-1.53613693e-01 -4.87828001e-01 -2.16840168e-01 -2.16543149e-02
-1.39973895e-03 -7.40929687e-05]
[1.99999013 1.99787943 1.8399713 1.71674076 1.98148809 1.58407415
1.91634063 1.9991646 1.99999651 1.99999999]
Name : GP regression
Objective : 3.2405297752729125
Number of Parameters : 3
Number of Optimization Parameters : 3
Updates : True
Parameters:
GP_regression. | value | constraints | priors
Mat52.variance | 1.0 | +ve |
Mat52.lengthscale | 1.0 | +ve |
Gaussian_noise.variance | 1e-15 | +ve |
results(noise_var~0) [-5.75795228e-03 -8.44113803e-02 -7.33727600e-01 -9.88413214e-01
-3.06567456e-01 -9.73202429e-01 -4.32586454e-01 -4.31993675e-02
-2.79241470e-03 -1.47812047e-04]
[0.99998026 0.99575881 0.67994023 0.43351368 0.96304576 0.16816651
0.83267985 0.99832918 0.99999302 0.99999998]
GPyでは、予測誤差がデフォルトで1.0に設定されていることがわかった。
これはかなり注意が必要。
GPに限らず多くの場合、データを標準化(平均0,分散1)して使うので、予測誤差の分散が1.0というデフォルト値を使うというのは、 「GPの予測が、データ全体の広がりと同程度誤差を持つ」ことを仮定していて、場合によっては非現実的な仮定になり得る。
Webに転がってるGPyを使ったコードだと、あまりこのあたりは認識されていないように思う。
GPyOpt#
上で自前コードでやったことを、GPyOptを使ってやってみよう。
#使うライブラリのインポート
!pip install GPy
!pip install GPyOpt
import GPy
import GPyOpt
import numpy as np
import matplotlib.pyplot as plt
Requirement already satisfied: GPy in /usr/local/lib/python3.7/dist-packages (1.10.0)
Requirement already satisfied: paramz>=0.9.0 in /usr/local/lib/python3.7/dist-packages (from GPy) (0.9.5)
Requirement already satisfied: cython>=0.29 in /usr/local/lib/python3.7/dist-packages (from GPy) (0.29.26)
Requirement already satisfied: scipy>=1.3.0 in /usr/local/lib/python3.7/dist-packages (from GPy) (1.4.1)
Requirement already satisfied: numpy>=1.7 in /usr/local/lib/python3.7/dist-packages (from GPy) (1.19.5)
Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from GPy) (1.15.0)
Requirement already satisfied: decorator>=4.0.10 in /usr/local/lib/python3.7/dist-packages (from paramz>=0.9.0->GPy) (4.4.2)
Collecting GPyOpt
Downloading GPyOpt-1.2.6.tar.gz (56 kB)
|████████████████████████████████| 56 kB 2.3 MB/s
?25hRequirement already satisfied: numpy>=1.7 in /usr/local/lib/python3.7/dist-packages (from GPyOpt) (1.19.5)
Requirement already satisfied: scipy>=0.16 in /usr/local/lib/python3.7/dist-packages (from GPyOpt) (1.4.1)
Requirement already satisfied: GPy>=1.8 in /usr/local/lib/python3.7/dist-packages (from GPyOpt) (1.10.0)
Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from GPy>=1.8->GPyOpt) (1.15.0)
Requirement already satisfied: cython>=0.29 in /usr/local/lib/python3.7/dist-packages (from GPy>=1.8->GPyOpt) (0.29.26)
Requirement already satisfied: paramz>=0.9.0 in /usr/local/lib/python3.7/dist-packages (from GPy>=1.8->GPyOpt) (0.9.5)
Requirement already satisfied: decorator>=4.0.10 in /usr/local/lib/python3.7/dist-packages (from paramz>=0.9.0->GPy>=1.8->GPyOpt) (4.4.2)
Building wheels for collected packages: GPyOpt
Building wheel for GPyOpt (setup.py) ... ?25l?25hdone
Created wheel for GPyOpt: filename=GPyOpt-1.2.6-py3-none-any.whl size=83609 sha256=b36359bb607ed1762b6fd67894ef7c988810df30bdafc0694e7c88cd11f5f48c
Stored in directory: /root/.cache/pip/wheels/e6/fa/d1/f9652b5af79f769a0ab74dbead7c7aea9a93c6bc74543fd3ec
Successfully built GPyOpt
Installing collected packages: GPyOpt
Successfully installed GPyOpt-1.2.6
def f(x): #GPyOptは最小値を探索するのでマイナスをかけておく
return - (np.sin(x) + 0.2 * x)
oxt = np.array([ 0.0 + 1.02*i for i in range(11)])
xt = np.array([ oxt[2], oxt[6]])
yt = f(xt)
xt = np.array( [ [ x ] for x in xt])
yt = np.array( [ [ y ] for y in yt])
## BayesOptの準備・実行
bounds = [{'name': 'x', 'type': 'continuous', 'domain': (-2,12)}]
res = GPyOpt.methods.BayesianOptimization(f=f,X=xt,Y=yt,
kernel=GPy.kern.Matern52(input_dim=len(bounds)),
domain=bounds,acquisition_type='EI')
#print("bounds", bounds,len(bounds))
res.run_optimization(max_iter=10)
## 結果の描画等
xs = res.X; ys = res.Y
print("Estimated Opt. x", res.x_opt[0], "y", -res.fx_opt)
xr = np.arange(-2.0,12.0,0.1)
yr = - f(xr)
fig = plt.figure(figsize=(12,4))
ax = fig.add_subplot(111)
ax.set_xlabel("x"); ax.set_ylabel("y")
ax.set_xlim(-2.0,12); ax.set_ylim(-2.0,5.0)
ax.plot(xr,yr,linestyle="dotted",color="red")
ax.scatter(xs,-ys,marker="o",color="black")
plt.show()
plt.close()
Estimated Opt. x 8.001075118805382 y 2.589416268802192