![]()
4. ライブラリ/パッケージ/モジュールとデータの可視化(Matplotlib)#
Pythonでは(他のプログラミング言語と同様)特定の作業がパッケージ化されたプログラム群が用意されていてこれらをライブラリ/パッケージ/モジュールなどと呼ぶ。 正確な定義としてはライブラリ/パッケージ/モジュールの順に、より上位の集合を指すが、 慣例的には同じ意味で使われることが多い。この授業でも呼び方が混在している。
Pythonのライブラリ/モジュールの多くはGitHub上で開発・公開されていて、簡単にインストールしたりインポートして使うことができる。 データ分析, AI・機械学習, エクセル等の操作, Webスクレイピングなど、非常に多岐にわたるライブラリが存在する。 Pythonのユーザー数が近年急増しているのは、こうしたライブラリが充実していることも大きな要因の一つである。
4.1. ライブラリのインポート(import)#
幾つかのライブラリ/モジュールは標準で組み込まれているため、特段インストール作業をすることなく、以下のように簡単にインポートして使うことができる。
たとえばmathという名前のモジュールをインポートする際には
import math
とする。カンタン。
このmathモジュールはPythonの標準ライブラリの一つで、数学関数を提供するモジュールである。
上のコードを実行しmathモジュールを一度importしてやれば、以降のコードで、
円周率\(\pi\):
pi自然対数:
log常用対数:
log10指数関数:
exp三角関数:
sin,cos
などを使うことができる。
モジュール内に用意されている定数や関数を利用するときは通常、モジュール名.定数やモジュール名.関数(引数)といった形で使う。
print(math.pi) #円周率pi
print(math.e) #ネイピア数e
print(math.log(2.0)) #自然対数
print(math.log10(2.0)) #常用(底が10)対数
print(math.exp(2.0)) #指数関数
print(math.sin(math.pi)) # sin(pi)
注:\(sin(\pi)\)は本来0だが、1章で述べたように実数が有限の精度なので、\(\pi\)の計算機上での数値が厳密には円周率と異なるため、\(sin(\pi)\)の値も僅かに0からズレることになる。
4.2. ライブラリのインストール#
Google Colaboratory環境では、Pythonの標準ライブラリ以外のライブラリを、pipコマンドを用いてインストールすることができる.
コードセルで以下のようにすれば良い:
!pip install package_name
ただし、Google Colaboratory環境では、よく使われるライブラリは標準でインストールされているので、
特殊なライブラリや特定のバージョンを使用したいといった状況でなければ、別途インストールする必要はない。
また、ユーザーが別途インストールしたライブラリは、そのセッションが終了すると消えてしまうので、
時間を空けて作業を再開する場合などは、毎回インストールする必要がある。
ローカルのPython環境におけるライブラリのインストールなどについては、
などを参照。
4.3. Numpy#
データ分析などで非常によく使われるNumpyというライブラリがある。
Numpyはおもにベクトルや行列の演算などを高速に行うことが可能という利点があり、データ分析においては必須のライブラリと言っても過言ではない。
ndarrayと呼ばれるNumpy独自の配列を用いることで、ベクトルや行列の演算を高速に行うことができたり、グラフの描画に配列を使う際にも便利な機能が用意されている。
簡単な作業ならリストでも代用できるので必須ではないが、コードを大幅に簡略化することもできるため、今後ノートブックでも適宜Numpyが用いられる。
Numpyの詳細についてはこちらのノートブックを参照。
Numpyはmathとも多くの互換性があるため、上で行った操作はNumpyでも代用できる:
import numpy as np #numpyをnpという名前で使う
print(np.log(2.0))
print(np.log10(2.0))
print(np.exp(2.0))
print(np.pi)
print(np.sin(np.pi))
また、以下でやるように、数値を要素に持つリストを使って演算やグラフを描画するときは、データのリストなどをndarray型に変換して使う事も多い。
リストをndarray型に変換するには、numpyのarray関数を用いればよい。
import numpy as np
list_a = [1.23, 9341.22, -32.33]
ndarray_a = np.array(list_a)
print(ndarray_a, type(ndarray_a))
グラフの描画で便利な理由は以下のような人単位のデータを持つ入れ子のリストがあったときに、成分の転置を取ってx軸方向のデータ, y軸方向のデータに整形が容易となる。
#身長体重のデータ
data = [ [180, 70], [175, 65], [160, 58], [170, 60] ]
print(data)
# データをndarrayに変換
data = np.array(data)
# 転置を行うメソッドを適用することで、0列目が身長、1列目が体重と整形できる
data = data.T
x = data[0]
y = data[1]
print(data)
print("x", x)
print("y", y)
なお、numpyのndarrayをprintすると上のようにデータを区切るカンマを省略したり、データの数が多いときは省略して表示してくれる。
これは、print関数がndarray型のデータを表示する際に、専用の表示方法を用いているためである。
4.4. Matplotlibを用いた作図#
次に、Matplotlibと呼ばれるライブラリを使って、各種のグラフを作成する方法を見ていこう.
Matplotlibは様々なグラフが描ける一方で少々テクニカルな部分が多いので細かい部分は分からなくても心配は不要である。 「こういうおまじないを唱える(書くと)こうなる」というざっくりとした理解でまずはOKなのでどんどん触りながら、少しずつ、グラフの詳細を調整する方法をマスターしていけば良い。 初めて作る料理についてはレシピを見ながら、2回目以降は少しアレンジを加えて、より自分好みの料理にしていくようなイメージが近いかもしれない。
Pythonのライブラリの細かな使い方を調べる時、真っ先に思いつくのがググることになるかと思う。 最近だと日本語で書かれた情報に気軽にアクセスできるのは良いことだが、不正確な記述が含まれていてかえって理解を遠ざける危険性もある。なにか困ったときに一番頼りになるのは大元のライブラリの公式ドキュメント以外ありえない。なぜなら開発者が作っているから。ページ内にあれこれと広告が貼り付けてあるようなブログ記事を見て、不正確な情報に振り回されたり不快な思いをするくらいなら、公式ドキュメントを参照しよう.
Matplotlibの公式ドキュメントは例えばこちら
はじめは授業資料にあるコードなどを少しずつ流用し、自分の目的のためにどうすれば良いか類推しながら改良していって、自分の描きたいグラフに近づけていくのが良い。(私もよく過去の自分が作成したコードを流用して作図している。) 慣れてくるといろんな図を作ったり、細かいところにこだわったりしたくなる。 そんなときは以下のチートシートが役につかもしれない。 matplotlib/cheatsheets
あるいは、最近だとChat GPTやGeminiなどのAIに「二次元配列をプロットするPythonコードを書いてください」「さっきのコードをさらに拡張して、棒グラフにハッチをつけてください」などと聞いてみても良いかも.
もちろん、コードを貼り付けるだけで個々の部品に関する理解を放棄しているといつまでたっても有効なプログラムを自分で書けるようにはならず、望むコードが生成されるまでAIに質問をし続けたり、誤りに気が付かずに間違った図を世に出す、という皮肉な状況に陥る恐れがある。その辺りのバランスを取りながら学習を進めよう。
4.4.1. Matplotlibのインポートと使い方#
まず、以下のコードを実行して、matplotlib内のpyplotモジュールをインポートしよう.
matplot.pyplotだと名前が長いのでpltという名前で使えるようにimport XXX as YY などとする.
import matplotlib.pyplot as plt
from matplotlib import pyplot as plt #でも同じ
いくつかのライブラリにはディレクトリのように
LibraryA
├ module1.py
│ └─ sub_module1_1.py
│ └─ sub_module1_2.py
├ module2.py
︙
という階層構造があり、子,孫,…といった下位のものはピリオドで指定する.
上のmatplotlib.pyplotはその一例になっている.
グラフ内で日本語を用いる際の注意事項
Matplotlibは標準だと日本語が文字化けして豆腐のように表示されてしまうので、日本語フォントを使うためのライブラリ、japanize-matplotlibをインストールしておく必要がある。
この作業は(japanize-matplotlibが標準でインストールされるようにならない限り)Google Colaboratory環境で作業を再開するたびに行う必要がある。 日本語を含むグラフを描画したければ必ずインストールしておこう。
セッション中は一度インストールしておけば、以降のセッションではインストールする必要はないので グラフの作成・描画など、繰り返し実行する可能性のあるセルとは分けておくと良い.
!pip install japanize-matplotlib #!から始めることでLinuxコマンドを使うことができる。
import japanize_matplotlib
import numpy as np
なお、ライブラリ名にハイフンが含まれる場合は、importする際にハイフンをアンダースコアに置き換える必要がある.
(ハイフンはPythonの変数名などに使えないため)
Pythonでグラフを作る際の基本は、データ(描画したいもの)が入った配列を作ることになる.
以下では、リスト-likeなデータ(例えばrangeやndarrayなど)を使って、グラフを描画する方法を見ていく.
毎回リスト-likeと書くのは面倒なので、以降はリスト-likeなデータを単にリストと呼ぶことにするが、
必ずしも描画につかうデータはリストに限らず、リストと互換性のあるndarrayなど、一般の配列も使えることに注意.
プログラムでグラフを描くのは、人間が手で絵やグラフを描く工程とは少し異なる. 線や棒、いろんな形のシンボルを描いたりして、どんどんグラフを構成する要素を足しながら、それらの色や線種、透過度や太さ,背景色などを変えつつ徐々に望むようなグラフにしていく作業になる. 場合によっては、どの要素を前面に配置するかといったレイヤーの意識も必要になる.
以下では代表的なグラフを例に、Matplotlibを使った作画を試してみよう.
4.4.2. 棒グラフ#
Aさんの共通テスト?の得点をリストとして定義してみよう 順番(各科目の名前(ラベル))は、国語,英語,数IA,数IIB,化学,物理,世界史,情報として…
data = [152, 170, 82, 85, 79, 92, 88, 100]
label = ["国語","英語(R+L)", "数IA", "数IIB", "化学", "物理", "世界史", "情報"]
total = sum(data)
print("合計得点は", total, "/1000 点で、得点率は"+str("%6.1f" % (100* total/1000))+"%です")
Aさん優秀。これを棒グラフにでもしてみよう。
plt.figure( figsize=(10,2) )
plt.bar(label,data,align='center',width=0.5,color="red")
plt.xlabel("各科目"); plt.ylabel("Aさんの得点")
plt.show()
plt.close()
1行目:
plt.figure(figsize=(10,2))上で
matplotlibモジュール内のpyplotというモジュールをpltという名前でインポートしたのでplt.figureというのはpyplot内のfigureという関数を使うことを意味する。その役割は、図を描くキャンバスを用意しているようなイメージ。
ここではfigsize=(10,2)という引数を指定した(指定しなければ自動で図のサイズが決まる).
figsize=(横,縦)で大きさが指定できるので、figsizeを変えて試してみよう2行目:
plt.bar(label,data,align='center',width=0.5,color="red")pyplot内のbarという関数(棒グラフを描く関数)を呼んでいる。1つめの引数はx軸上の値で、2つめはy軸に対応する値
x軸用のリストが数値以外のときは整数値を割り当ててプロットしてくれる(7個データがあれば、x=0,1,…,6に割り当てられる)。3行目:
plt.xlabel("各科目"); plt.ylabel("Aさんの得点")ここではx軸とy軸のデータの種類(ラベル/labelと呼ぶ)を指定している。
4行目:
plt.show()それまでに指定した条件で絵を描いて表示する
5行目:
plt.close()キャンバスを閉じる。とくに一つのプログラムで複数絵を描くときはこれを書く必要がある。 (closeしないと、どこまでがどのグラフのための指示かわからず意図しない絵になることがあります)
ライブラリを使用する際には、見慣れない関数がたくさん出てくるので、その全てについて今の段階でオプションの指定の仕方を覚える必要はない. とりあえず、既に指定されているオプションのいくつかを変更してみよう。
その際、colorやwidth, alignなどから「widthは数値だから増減するとどうなるかな?」「align="center"がいけるならleftとかrightもあるか?」「こう変えるとこうなるんじゃ…?」と類推しながらやってみよう。
練習
いくつかの得点や、棒グラフの色・幅を変えてプロットしてみよう。
例えばcolorの場合、一般的な色の名前を指定するか、カラーコード(真っ黒=”#000000”など)やRGBの値(0~1の値を3つ並べたもの,例->(0.2,0.5,1))を指定することで色を変更できる。
※日本語が上手く表示されない場合、上のjapanize_matplotlibをインストールする行の実行を忘れている.
4.4.3. plot: 線の描画#
説明変数\(x\)と目的変数\(y\)があって、とくに \(x\)に対する\(y\)の振る舞い に興味がある場合にはplotを使う。
例として、以下に日本の一人当たりGDP($, 購買力平価・インフレ調整済)の推定値をリストとして与えた。 これを線グラフにしてみよう。
x = [1800, 1801, 1802, 1803, 1804, 1805, 1806, 1807, 1808, 1809, 1810, 1811, 1812, 1813, 1814, 1815, 1816, 1817, 1818, 1819, 1820, 1821, 1822, 1823, 1824, 1825, 1826, 1827, 1828, 1829, 1830, 1831, 1832, 1833, 1834, 1835, 1836, 1837, 1838, 1839, 1840, 1841, 1842, 1843, 1844, 1845, 1846, 1847, 1848, 1849, 1850, 1851, 1852, 1853, 1854, 1855, 1856, 1857, 1858, 1859, 1860, 1861, 1862, 1863, 1864, 1865, 1866, 1867, 1868, 1869, 1870, 1871, 1872, 1873, 1874, 1875, 1876, 1877, 1878, 1879, 1880, 1881, 1882, 1883, 1884, 1885, 1886, 1887, 1888, 1889, 1890, 1891, 1892, 1893, 1894, 1895, 1896, 1897, 1898, 1899, 1900, 1901, 1902, 1903, 1904, 1905, 1906, 1907, 1908, 1909, 1910, 1911, 1912, 1913, 1914, 1915, 1916, 1917, 1918, 1919, 1920, 1921, 1922, 1923, 1924, 1925, 1926, 1927, 1928, 1929, 1930, 1931, 1932, 1933, 1934, 1935, 1936, 1937, 1938, 1939, 1940, 1941, 1942, 1943, 1944, 1945, 1946, 1947, 1948, 1949, 1950, 1951, 1952, 1953, 1954, 1955, 1956, 1957, 1958, 1959, 1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, 1971, 1972, 1973, 1974, 1975, 1976, 1977, 1978, 1979, 1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989, 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024, 2025, 2026, 2027, 2028, 2029, 2030, 2031, 2032, 2033, 2034, 2035, 2036, 2037, 2038, 2039, 2040]
y = [1050, 1050, 1050, 1050, 1060, 1060, 1060, 1060, 1060, 1060, 1060, 1070, 1070, 1070, 1070, 1070, 1070, 1070, 1080, 1080, 1080, 1080, 1080, 1080, 1090, 1090, 1090, 1090, 1090, 1090, 1090, 1100, 1100, 1100, 1100, 1100, 1100, 1100, 1110, 1110, 1110, 1110, 1110, 1110, 1120, 1120, 1120, 1120, 1120, 1120, 1130, 1130, 1130, 1140, 1140, 1150, 1150, 1150, 1160, 1160, 1170, 1170, 1180, 1180, 1190, 1190, 1190, 1200, 1200, 1210, 1210, 1220, 1220, 1230, 1230, 1320, 1280, 1300, 1290, 1350, 1390, 1340, 1360, 1350, 1340, 1380, 1460, 1520, 1430, 1480, 1610, 1520, 1600, 1590, 1760, 1770, 1650, 1660, 1950, 1790, 1840, 1880, 1750, 1850, 1840, 1790, 2000, 2040, 2030, 2000, 2000, 2070, 2100, 2100, 2000, 2150, 2440, 2480, 2480, 2700, 2500, 2720, 2670, 2630, 2650, 2710, 2680, 2660, 2830, 2860, 2600, 2570, 2740, 2950, 2900, 2920, 3090, 3180, 3350, 3850, 3920, 3910, 3830, 3830, 3600, 1820, 1950, 2080, 2320, 2420, 2580, 2760, 3060, 3210, 3330, 3520, 3700, 3900, 4060, 4360, 4840, 5370, 5790, 6220, 6870, 7190, 7880, 8630, 9640, 10800, 14500, 15000, 16100, 17100, 16700, 17000, 17500, 18100, 19000, 19800, 20300, 21000, 21500, 22000, 22900, 24200, 24800, 25700, 27500, 28900, 30400, 31400, 31500, 31500, 31700, 32400, 33300, 33600, 33200, 33000, 33900, 33900, 33900, 34300, 35100, 35700, 36100, 36700, 36300, 34300, 35800, 35800, 36400, 37100, 37300, 37800, 38200, 38600, 39100, 39400, 39800, 40300, 40800, 41400, 42100, 42900, 43700, 44600, 45600, 46500, 47600, 48600, 49700, 50800, 51900, 53100, 54300, 55500, 56700, 57900, 59200]
plot関数は多数の引数を受け取ることができる。
まずは最小の引数であるyだけを指定してみよう。
fig = plt.figure(figsize=(12, 4))
plt.plot(y, color="blue")
plt.show()
xを省略すると、0から始まる整数値が自動的に割り当てられる。 したがって、あるデータを起点に経過日数などで表す場合は、xを省略しても良い。 より一般の場合は、xを指定してやると良い。
fig = plt.figure(figsize=(12, 4))
plt.plot(x, y, color="red", linewidth=1, label = "Japan")
plt.show()
カラーコードで色を指定、x軸ラベル, y軸ラベル, legend(判例), y軸のスケールをlogにするなど、 より複雑なオプションを指定してみよう.
fig = plt.figure(figsize=(12, 4))
plt.plot(x, y, color="#006036", linewidth=1, label = "Japan")
plt.xlabel("年") # x軸のラベル
plt.ylabel("GDP[$]") # y軸のラベル
plt.yscale("log") # y軸を対数スケールにする
plt.legend(loc="upper left") # 凡例の位置を指定して表示
plt.show()
当然だが、x軸とy軸方向でデータの数が合っていないとエラーとなる.
「一緒にしているつもりなのにエラーが出る…」と言う場合は、len関数を使うなどして、リストの長さ/要素の数をチェックしてみよう。
カンマがピリオドになっていて数がずれる、といったことがよくある。
例:
(意図したリスト) [2,3,5] ←長さ3のリスト
(間違えて作ったリスト) [2.3, 5] ←カンマがピリオドになっていて、長さ2のリストになっている.
上記のようなミスを防ぐには、値を入力してカンマを打ったあと半角スペースを開けるようにすると分かりやすい, [2,3,5]→[2, 3, 5].
カンマの後ろにスペースを入れることは文法上の必要条件ではないが、コードの可読性を上げるために推奨される書き方である. 英文などでも基本となるため、癖づけておくと良い.
凡例について
上でも少し凡例について触れたが、barやplot、以下でやるscatterなどそれぞれのグラフを構成するオブジェクトに対して、labelという引数を指定することで凡例を付けることができる.
とくに複数のデータをまとめてプロットするときは、どのデータがどの線や棒に対応するのか分からなくなってしまうことがあるので、凡例をつけることが重要になる。用意した凡例はplt.legend()で有効化することができる.
凡例を設定することは、図の可読性を向上させるための重要な要素である一方で、 同じような色や形の凡例が多すぎると、かえって可読性を下げてしまうこともある。 例えば、散布図で一点ごとに描画してlabelをつけてしまうと、データの数だけ凡例ができてしまいとても不格好なグラフになってしまう。
最小限の数の凡例をつけるようデータを整形したり、凡例の一部をannotationにしたり、 図の横側に凡例を置いたりなど工夫が必要になることも多い。
4.4.4. scatter: 散布図の描画#
\(x\)と\(y\)、2つの量があって、どちらにも興味がある、
あるいは両者の間の相関に興味がある場合、散布図を描くと、見通しやすくなることが多い。
以下では、2017年の宇都宮の平均気温とアイスクリームの消費量の相関を見てみよう。
気温・アイスクリームの消費量ともに、1月から12月に順番にリストに入れていくことにする。
※実際のデータ分析の場合は、手でデータを入力してリストを作るのは面倒な上、人為的なミスが入り込む可能性が高いので、CSVファイルなどからデータを読み込むべきである。そうすると、ミスがあってもデータを作成した人のせいにできる、というより責任やミスの所在を明確にできる。
x= [3.1, 4.3, 6.6, 13.2, 19.1, 20.9, 26.4, 25.1, 21.9, 15.7, 9.6, 3.8]
y= [568, 572, 804, 833, 930, 965, 1213, 1120, 835, 540, 451, 502]
plt.figure(figsize=(4,4))
plt.title("宇都宮市") ## 図にはタイトルをつけることができます
plt.xlabel("平均気温 (℃)") #軸ラベルの指定
plt.ylabel("世帯あたりのアイスクリーム・シャーベットの消費金額 (円)")
plt.scatter(x,y)
plt.show()
plt.close()
相関係数などの情報を含んだもう少し凝った図を作ってみよう:
x= [3.1, 4.3, 6.6, 13.2, 19.1, 20.9, 26.4, 25.1, 21.9, 15.7, 9.6, 3.8]
y= [568, 572, 804, 833, 930, 965, 1213, 1120, 835, 540, 451, 502]
# Numpyを使ってx,yの配列間の相関行列を計算. 詳細は相関分析の際に.
r = np.corrcoef(x,y)
corrcoef = r[0,1] #相関行列rの(0,1)成分を取り出す
#季節ごとに適当に色を塗るために、月を入力すると色を返す関数を定義
def seasoncolor(month):
if month <= 2 or month ==12:
return "blue"
elif 3 <= month <=5:
return "green"
elif 6 <= month <=8:
return "red"
elif 9<= month <=11:
return "orange"
else:
print("month",month, " is not supported")
# 図の描画部分
fig = plt.figure(figsize=(5,5))
ax = fig.add_subplot(111) #fig.add_subplot(1,1,1)と等価. 1行1列の1番目のグラフをaxとして取得
ax.set_facecolor("#D3DEF1")
ax.set_title("宇都宮市")
ax.set_xlabel("平均気温 (℃)")
ax.set_ylabel("世帯あたりのアイスクリーム・シャーベットの消費金額 (円)")
ax.grid(True,axis="both",color="w", linestyle="dotted", linewidth=0.8)
for i in range(len(x)):
tcol=seasoncolor(i+1)
ax.scatter(x[i],y[i],marker="o",s=20,color=tcol,zorder=20000,alpha=0.7)
ax.text(x[i],y[i],str(i+1)+"月",color="k",fontsize=8, ha = "left", va = "bottom")
ax.text(0.1,0.9, "r="+str("%5.2f" % corrcoef), transform=ax.transAxes,fontsize=12)
plt.show()
plt.close()
4.4.5. \(\clubsuit\) ax (matplotlib.axes) #
上では、axという見慣れないものが導入されている。
キャンバスの上に小さな作業領域axesを指定するためのadd_subplotやadd_axesといった関数がある。
axはこれらの関数で生成される作業領域に慣例的に用いる変数名で、とくに作業領域が一つの場合によく用いる。
axesを使うと、キャンバス上に複数のグラフを描くことができるので、たとえばキャンバスを四分割して、似たようなグラフを4つ同時に描いたりするのに便利.
axesを使いこなすのは少々テクニカルな点も多いので、よくわからない部分はとりあえず飛ばし読みで構わない。
使いこなせれば、論文に使う図表を作るなど、大変重宝するはずだ。細かい図の書き方は必要に応じて勉強していこう.
axesに関しては、日本語で書かれた以下の記事もおすすめ:
https://qiita.com/skotaro/items/08dc0b8c5704c94eafb9
下ではadd_subplotを使って、キャンバス上に小さな作業領域を作成している.
add_suplotの引数は、(行数, 列数, 作業領域番号)で、
3行2列の作業領域を作成する場合、左上から右下に向かって1,2,3,…と番号が振られる.
行数・列数・作業領域番号は整数で指定するが、いずれも10未満の場合であれば、
連続して書くことでも同じ意味になる.
具体的には、add_subplot(3,2,1)はadd_subplot(321)とも書けるが、
add_subplot(3,2,10)はadd_subplot(3210)とは書けない(全て一桁で無いとambiguityが生じるため).
fig = plt.figure(figsize=(10,5))
axTL = fig.add_subplot(2,2,1) #TL: Top Leftのつもり
axTR = fig.add_subplot(2,2,2) #TR: Top Rightのつもり
axBL = fig.add_subplot(2,2,3) #BL: Bottom Leftのつもり
axBR = fig.add_subplot(2,2,4) #BR: Bottom rightのつもり
axTL.plot(data)
axTR.scatter(x,y)
axBL.bar(label,data,align='center',width=0.5,color="red")
axBR.text(0.5,0.4,"右下だよ")
plt.show()
plt.close()
4.4.6. Google Drive上のファイル操作&Google Colab.上で作ったグラフの保存#
プログラムを実行して絵を描けるようになったら、次にそれを保存して、レポートに貼り付けたり、誰かに送ったりする必要が出てくる。
Google Colab.では、同じGoogleのサービスであるGoogle drive上にファイルを保存したり保存したファイルを他人と共有することができる。
皆さんのアカウントのGoogle Driveにあるファイルに、Google Colab.からアクセスするためにはマウントという作業が必要になる。
from google.colab import drive
drive.mount('/content/drive') # ←のマウントする際の名前は好きに決められる。drive.mount('gdrive')とかでもOK
上のコードを実行し(複数アカウントを所持している方はアカウントの選択をして)ポップアップ等の指示に従い操作を行う。 成功すると、Mounted at ほにゃららというメッセージが出る。
上のコード2行目は「google driveをdriveという名前でマウントする」という操作を表していて、 マウントできていれば、以下のコードを実行すると、皆さんのアカウントのマイドライブ直下のファイル一覧が表示される。
!ls ./drive/MyDrive
Google Colab.からは、!マークをつけることでLinuxコマンドが使える.
上のlsというコマンドは(List Segmentsの略で)ファイルやディレクトリの情報を表示するコマンド。
半角のスラッシュ/はディレクトリ階層を意味していて、Windowsで言うところの¥に相当する。
コンピュータでディレクトリやパスを指定するときは通常このようなパスと呼ばれるものを指定して扱う(※パスについてはファイル操作のノートに詳しい記述がある).
次に、GoogleDriveに、図を保存する用のフォルダを作っておこう.
mkdir(make directoryの略)コマンドで、マイドライブ直下にColab_picというディレクトリを作ることにします.
!mkdir './drive/MyDrive/Colab_pic'
上のコードを実行後にエラーが出ていなければGoogle Driveを開くとColab_picというディレクトリが作成されているはず。
一度フォルダを作ってしまうと、2回目以降は上のコードを実行しても「既にフォルダありますよ!!」というメッセージがでるため、ノートを開く度といったように複数回実行する必要はない。
これで準備ができた。試しに以下のコードを実行して図を保存してみよう。
# 先程の図
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(1,1,1)
ax.set_facecolor("#D3DEF1")
ax.set_title("宇都宮市")
ax.set_xlabel("平均気温 (℃)")
ax.set_ylabel("世帯あたりのアイスクリム・シャーベットの消費金額 (円)")
ax.grid(True,axis="both",color="w", linestyle="dotted", linewidth=0.8)
for i in range(len(x)):
tcol=seasoncolor(i+1)
ax.scatter(x[i],y[i],marker="o",s=10,color=tcol,zorder=20000,alpha=0.7)
ax.text(x[i],y[i],str(i+1)+"月",color="k",fontsize=8)
ax.text(0.1,0.9, "r="+str("%5.2f" % corrcoef), transform=ax.transAxes,fontsize=12)
###plt.show()の代わりに、savefigというメソッドを使い、グラフを保存する
plt.savefig("./drive/My Drive/Colab_pic/scatter_Utsunomiya_ice.pdf")
plt.close()
上のコードを実行後にGoogle Drive上の指定したフォルダを確認してみよう.
少しラグがあるかもしれないが、少し待つと、フォルダ内にscatter_Utsunomiya_ice.pdfというpdfファイルが出来る。
Matplotlibはファイル名を変えるだけで、指定した拡張子で描画してくれるので色々試してみよう(.jpg,.pdf,.eps,.pngなど)
注意
savefig()関数の前にshow()を実行するとその時点でキャンバスがクリアされるので、savefig()で保存したファイルが空になってしまうので注意.
show()はsavefig()の後に実行すること.
余談
プレゼンのスライドに載せる画像は可能な限り、ラスタ形式ではなくベクタ形式(pdfなど)にしよう。 (あるいは、高解像度でjpegやpngを作ってスライドを作り、誰かにスライドを渡すときは軽量化する) 線がガビガビの図だらけスライドを使ったスライドは「あぁ配慮が足りないんだな」と思われて損をしてしまうかもしれない。 例えば、プレプリントサーバーであるarXivには毎日多くの論文がアップロードされているが、 論文の体を為していない文章や、いわゆる「トンデモ論文」といって、科学的なプロセスを踏んでいない論文も稀にある。 そうした論文に共通する特徴の一つとして、図の解像度が酷く低いことが挙げられる。 もちろん必要十分条件ではないが、マトモな論文である蓋然性は低くなる。
4.4.7. gifアニメーションの作成#
「なんだこの程度のグラフならExcelでも簡単にできるじゃん…」と思った皆さんのために、もう少し凝ったことをやってみましょう。
以下のリンクに、x軸をGDP,y軸を24歳から35歳の平均就学年数の女性/男性比(%)としたグラフを画像ファイル(png)にしたものを公開した。
もともとのデータはFACTFULNESSから来ているのでライセンスフリー.
そのデータをもとに、Pythonで幾つかの国のデータを抜き出して、グラフを作成してある。
https://drive.google.com/file/d/1-Ko1pY3Pk4Wf05qMiMPFP9Yu-DM4vhpX/view?usp=sharing
この画像ファイルをパラパラ漫画のようにしてgifアニメーションにしてみよう. そのために必要なファイルにGoogle Colab.からアクセスできるよう、以下のいずれかの手順で作業しよう(授業ではより簡単な2を使う予定)
4.4.7.1. 方法1: Google Driveを開いて直接操作する方法#
まず上記リンクからダウンロード
Zip形式なので、それを解凍する
解凍したフォルダを自身のGoogle Driveの好きな場所にアップロードする ※以下のグラフを作成するコードをそのまま使いたければマイドライブ直下にアップロード
つまり、アップロードされた画像ファイルが、マイドライブ→GDPvsWomenInSchoolという階層にある状態になる。
4.4.7.2. 方法2: LinuxコマンドとPythonコードで行う方法#
zipを解凍するソフトウェアが無い方はこちらがおすすめ:
Google Driveをマウントしておく
Pythonコードを使って、共有リンクからzipファイルを保存する
zipファイルをunzipコマンドで展開し、展開したフォルダをGoogle Driveのフォルダに移動する
# 手順 1. Driveのマウントがまだ未実行であればコメントアウトを外して実行
#from google.colab import drive
#drive.mount('/content/drive')
# 手順 2. Pythonコード
import urllib.request
import sys
url = "https://drive.google.com/uc?export=download&id=1-Ko1pY3Pk4Wf05qMiMPFP9Yu-DM4vhpX"
filename = "GDPvsWomenInSchool.zip"
urllib.request.urlretrieve(url,filename)
# 手順3. Linuxコマンド (Google Colab.上では、!から始めることでLinuxコマンドを使うことができる)
#zipファイルを解凍する (-oオプションは上書き解凍, 何回か実行してもエラーにならないように)
!unzip -o GDPvsWomenInSchool.zip
#解凍したファイルをマイドライブ直下へ(マウントした状態でないと無効)
!mv GDPvsWomenInSchool drive/MyDrive/
4.4.7.3. pngファイルを読み込んでgifアニメーションを作成する#
先程のグラフがgoogle driveに保存されているかどうかは、以下のコマンドで確認できる(アップロードして直後はファイルが見つからないことがある).
!ls ./drive/MyDrive/GDPvsWomenInSchool/*.png
GDPvsWomenInSchool/の部分は、もし独自のフォルダなどを用意した場合は、対応するフォルダ名に適宜変更すること。
ファイルが確認できたら、年代ごとに別々になったたくさんのグラフを、1つのパラパラ漫画にまとめてみよう。
pngファイルをまとめてgifにするコードは以下の通り(処理にしばし時間がかかる):
from PIL import Image
import glob
# まとめたいpngをワイルドカード*で指定
files = sorted(glob.glob('./drive/My Drive/GDPvsWomenInSchool/GDPvsWomen*.png'))
images = list(map(lambda file: Image.open(file), files))
# 出力名と保存場所を指定
oupf = './drive/My Drive/Colab_pic/GDPvsWomen.gif'
# 画像をGIFアニメーションとして保存
images[0].save(oupf, save_all=True, append_images=images[1:], duration=400, loop=0)
エラーが出なければ、変数oupfで指定した場所に、gifファイルが生成されている。
作成例: ファイルへのリンクはこちら
{kind=link}
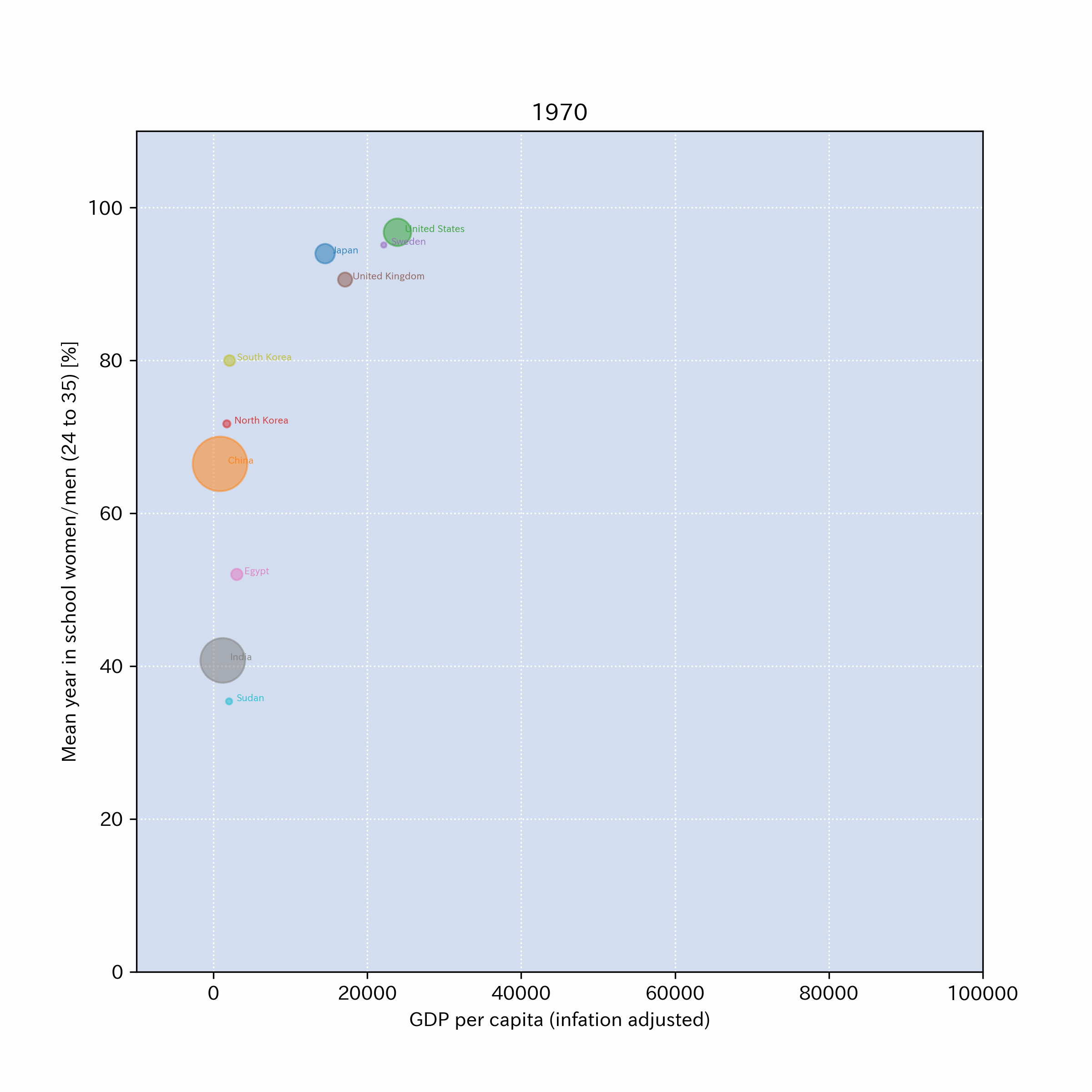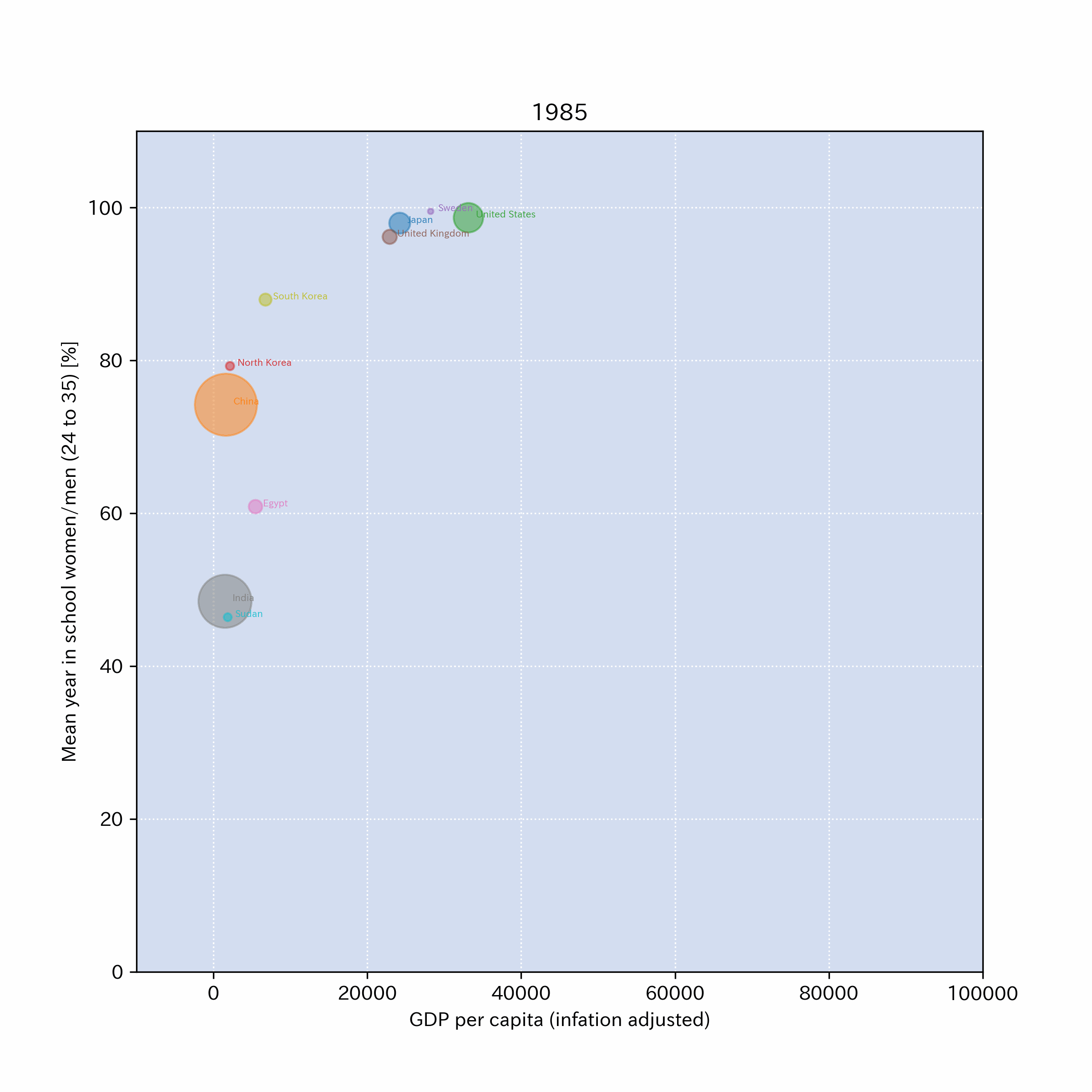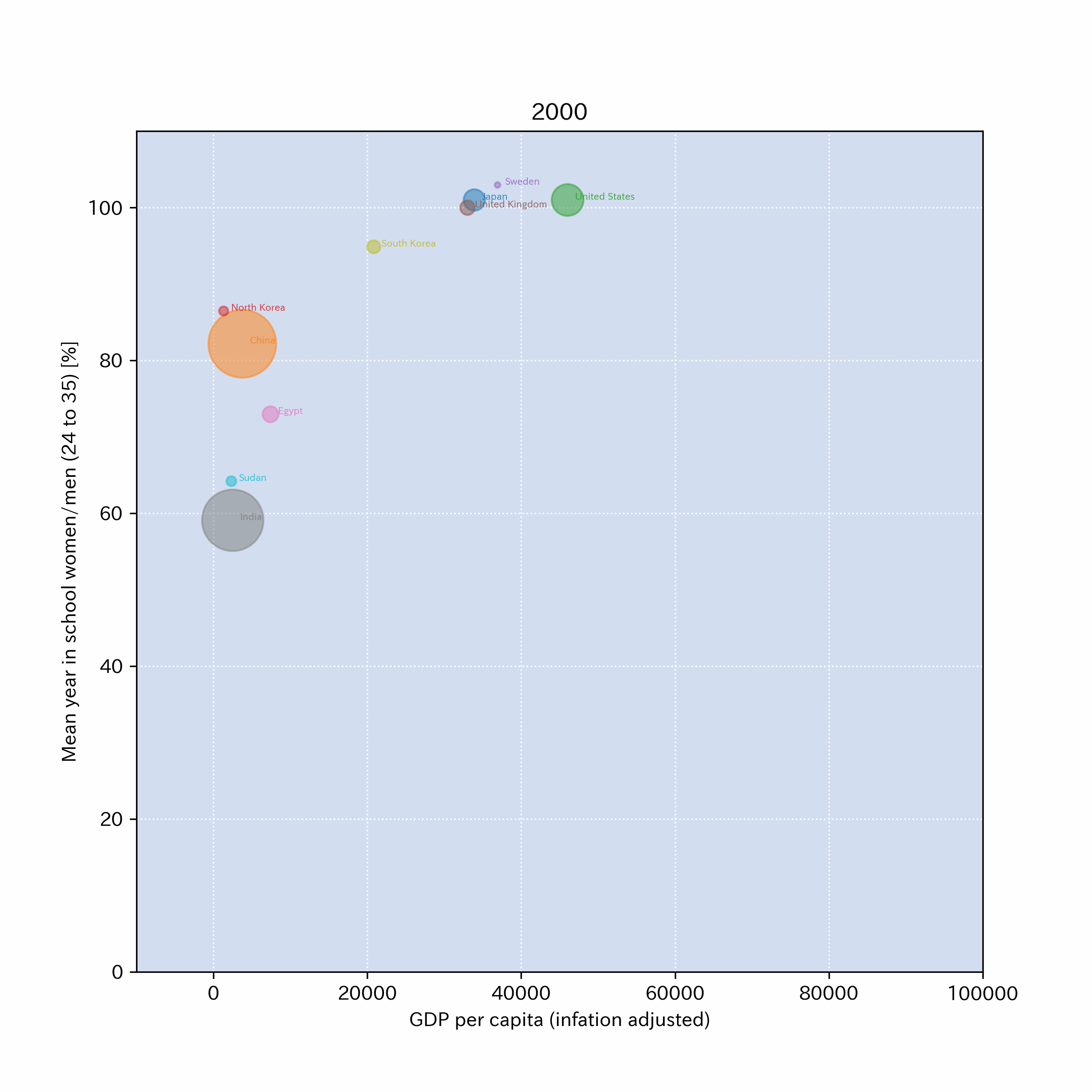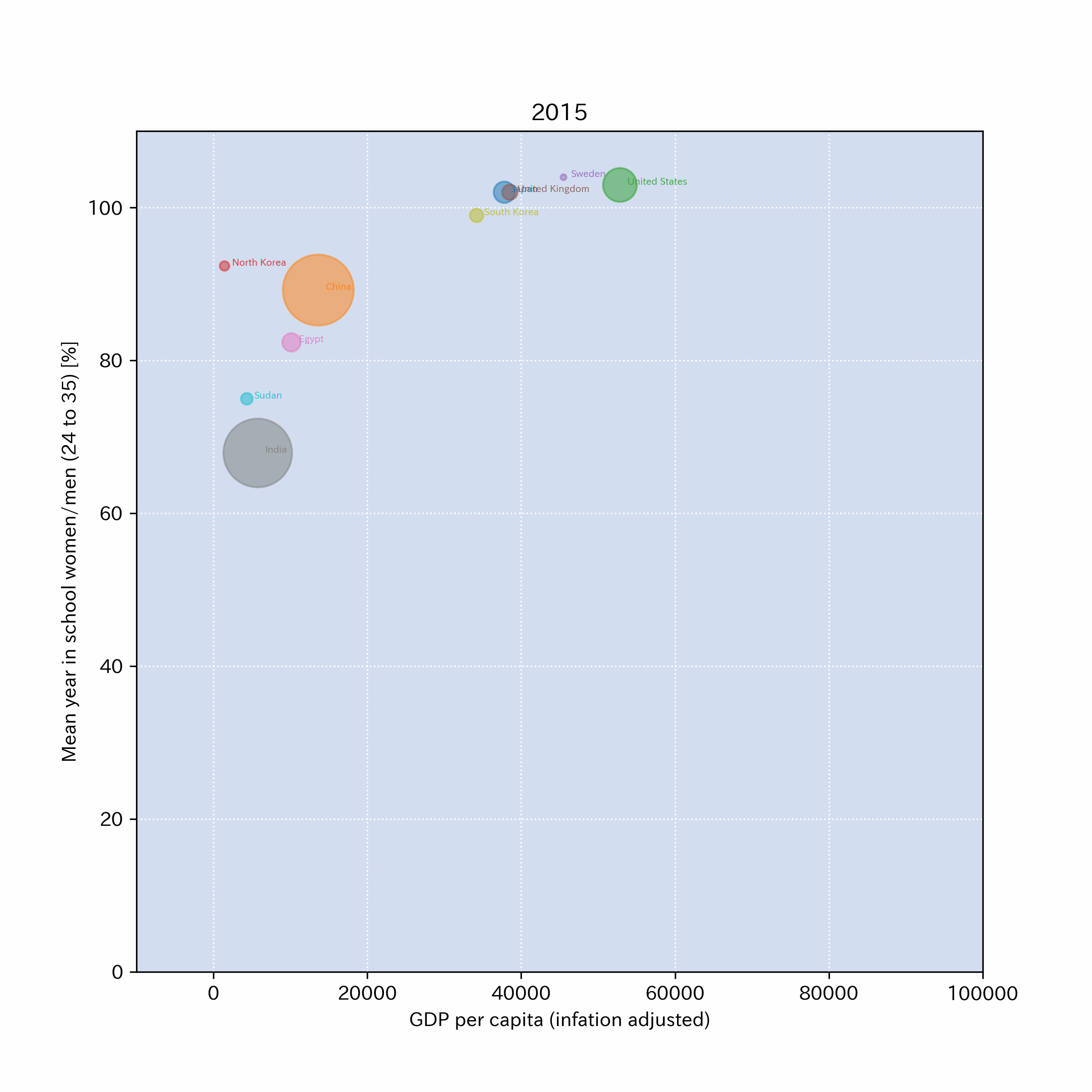
4.4.8. \(\clubsuit\)おまけ#
その他のグラフ
二次元ヒストグラム
import matplotlib.cm as cm
import numpy as np
mu1 = [ 3.0, 2.0]
cov1 = [ [1.0, 0.7],[0.7,1.0]]
numS = 50000
sample1 = np.random.multivariate_normal(mu1,cov1,numS)
x1, y1 = sample1.T
fig = plt.figure(figsize=(6,5))
ax1 = fig.add_subplot(111)
H1 = ax1.hist2d(x1,y1, bins=40, cmap=cm.jet)
ax1.scatter(mu1[0],mu1[1],color="k",marker="x")
ax1.set_title('sample1')
ax1.set_xlabel('x'); ax1.set_ylabel('y')
fig.colorbar(H1[3],ax=ax1)
plt.show()
plt.close()
日本地図
!pip install japanmap
from japanmap import pref_names,pref_code,groups,picture
import matplotlib.pyplot as plt
from pylab import rcParams
plt.figure(figsize=(6,6))
plt.imshow(picture({'栃木県': 'red', '群馬県': 'blue'}))
4.5. 色に関する注意#
色は、データの可視化において非常に重要な要素である.一方で、色は人間の感覚に依存するため、その選択には注意が必要である。
例えば、男性の20人に1人程度の割合で何らかの色覚異常があるとされている。
Pythonでは、カラーマップやパレットといった、色の選択を補助するための機能が用意されているが、
カラーマップの中にも、colorblind friendlyなものが用意されており、学術論文などでも、色覚異常の読者に対する配慮が求められることがある。
自分が見ている世界と、他人が見ている世界は異なるという事実を意識するのは、色に限らずコミュニケーションなどにおいても重要である。