![]()
機械学習: ニューラルネットワークによる回帰#
この章では、最も単純な、入力層・隠れ層・出力層からなるニューラルネットワークを使って、データから尤もらしい予測を与える関数を構築してみましょう。
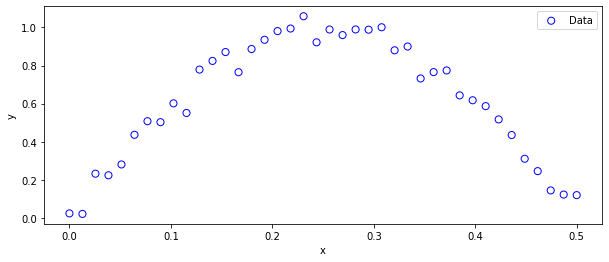
対象とする(疑似)データは、多項式回帰の際に用いたデータと同じsin関数+ノイズで生成することにします。
すすんだ注: このノートブックでは「ニューラルネットワークをPythonで表現してみる」ことに重きをおくため、使用するデータを訓練データ,検証データ,テストデータに分けることはせず、データは全てニューラルネットワークの訓練データとして使うこととします。 授業で説明するとおり、一般に[教師あり学習]の文脈でニューラルネットワークを考える際は、本来データを上の様に複数用途に分けながら、モデル選択を行ったり、汎化性能の評価に使ったりします。
import numpy as np
def create_toy_data(sample_size, std):
np.random.seed(1234) #毎回同じデータになるように乱数の種を固定しておく
x = np.linspace(0, 0.5, sample_size)
t = np.sin(2*np.pi*x) + np.random.normal(scale=std, size=x.shape)
return x, t
xt,yt = create_toy_data(40,5.e-2)
###グラフにしてみる
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,4))
ax = fig.add_subplot(111)
ax.set_xlabel("x"); ax.set_ylabel("y")
ax.scatter(xt, yt, facecolor="none", edgecolor="b", s=50, label="Data")
ax.legend()
plt.show()
plt.close()
ではいくつか必要な関数を適宜定義しながら進めていきましょう。
*注: 以下のコードは入力・出力ともに1次元かつ、決まったニューラルネットワーク構造の場合に対して書かれているため、naiveに2層以上の隠れ層を持つニューラルネットワークに拡張するのはstraightfowardではなく、また効率的ではありません。
nhl = 8 ## 隠れ層のノードの数を指定 これを増やすほどニューラルネットワークの表現能力が上がる一方、データに過適合しやすくなる(例外あり)
#重み行列W,V(今はベクトル)と、隠れ層でのバイアスbs,出力層でのバイアスを正規乱数で初期化
np.random.seed(1234) #結果が実行ごとに同じになるよう乱数を固定(バグを見つけやすくする)
W = np.random.normal(0.0,1.0,nhl)
V = np.random.normal(0.0,1.0,nhl)
bs = np.random.normal(0.0,1.0,nhl)
b0 = np.random.normal()
隠れ層で作用させる活性化関数を定義しておきましょう。
#シグモイド関数: 活性化関数の一つ
def sigmoid(z):
return 1.0/(1.0+np.exp(-z))
最適化したい量(データとモデルの齟齬を表す量)を目的関数(target function)やloss functionなどと呼びます。(以下でもそれに倣う)
以下では、データとANNのアウトプットの二乗誤差を目的関数として定めることにします。
### データとANNの出力間の二乗誤差を計算する関数を作っておく。
def calc_tloss(x,y,tW,tV,tbs,tb0,acf):
nhl = len(tW)
s=0.0
for i in range(len(x)):
s += (np.dot(tV, acf(tW*x[i]+tbs)) + tb0 - y[i])**2
return s
上ではcalc_tlossの引数にacfという変数を指定し、acfにsigmoidを指定しました。
この様にしておくと、sigmoid関数以外の活性化関数を使う際にも、上のcalc_tloss関数が使いまわせますね。
データの下処理#
機械学習などの分析では、データの値を中心0,分散1に変換して扱うのが基本です。
このことを、データの標準化と呼びます。
ymean = np.mean(yt)
ystd = np.std(yt)
ny = (np.array(yt)-ymean)/ ystd #それぞれのデータを平均をひいて標準偏差で割る
なぜ標準化が必要なのかは、今のような1次元入力データの場合よりもむしろ多変数を扱う際を考えてみるとわかります。
変数ごとに標準的なスケールが違う値を扱う場合、スケールの大きな量に学習が引っ張られる、ということが起こりえます。
たとえば目的関数を[体重と身長、それぞれについての二乗誤差の和]とする場合、
データが50kg、ニューラルネットワークの予測が55kgで10%違っていても、二乗誤差の値は25ですが、
身長が180cm vs 198cmと10%違っていたら、二乗誤差の値は324となります。
したがって、目的関数は身長の予測精度により強く依存することになり、
身長をより重視する(きちんと再現する)方向へ、ニューラルネットワークの学習が引っ張られてしまいます。
もちろん、身長をより高い精度で推測したいニューラルネットワークを構築したいなら話は別ですが、
特定の値を特別視しない(全ての量を平等に扱う)のなら、通常は標準化を行います。
acf = sigmoid #sigmoid関数をacfという名前で使う
さて、初期値W,V,bs,b0と活性化関数にsigmoidを選んだニューラルネットワークとデータの値の二乗誤差は…
print("初期値での二乗誤差",calc_tloss(xt,ny,W,V,bs,b0,acf))
初期値での二乗誤差 61.29358546868393
データ1個あたり、ニューラルネットワークとデータ値との間にどれくらい誤差があるかというと…
print("データ1個あたりの誤差:", np.sqrt(calc_tloss(xt,ny,W,V,bs,b0,acf)/len(xt))) #データ1個あたりどれほど誤差*があるか *標準化された誤差
データ1個あたりの誤差: 1.2378770684995737
ランダムに生成した重み(W,V)やバイアス項(bs,b0)では、まだニューラルネットワークは訓練がなされていないデタラメな関数なので、図にプロットしてみると…
xp = np.linspace(0.0,0.5,300)
yp = np.array([np.dot(V, sigmoid(W*xp[i]+bs)) for i in range(len(xp))])
fig = plt.figure(figsize=(10,4))
ax = fig.add_subplot(111)
ax.set_xlabel("x"); ax.set_ylabel("y")
ax.scatter(xt, yt, facecolor="none", edgecolor="b", s=50, label="Data")
ax.plot(xp,yp*ystd+ymean,label="ANN") #ニューラルネットワークの予測ypは、"標準化された"yの値に従って学習されているので、元のスケールに戻さないといけない。
ax.legend()
plt.show(); plt.close()
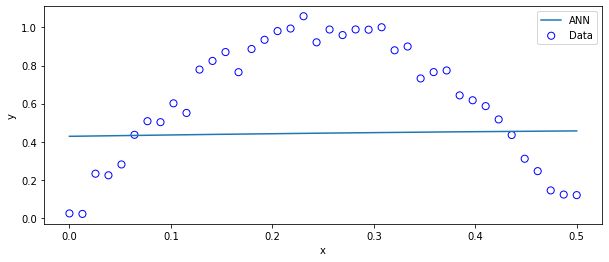
当然ですが、全然だめですね。
状況を改善するためにニューラルネットワークのパラメータを徐々に更新(学習)していきましょう。
そのためには、まず勾配を計算する関数を用意しておきます。
loss functionを\(f\)と書くことにすると、必要な勾配は4種類で
\(\frac{\partial f}{\partial W}, \frac{\partial f}{\partial V}, \frac{\partial f}{\partial b}, \frac{\partial f}{\partial b_0}\)です。
プログラムではそれぞれdw,dv,dbs,db0とでも名前をつけることにして、勾配を返り値として与える関数を定義します。
以下では、勾配降下法, Adamの2通りの最適化手法を用いてパラメータを更新することとします。
勾配降下法#
勾配降下法とは、目的関数を微分した勾配の値のみを使ってパラメータを更新する方法です。
たとえば,重み\(W\)の\(i\)番目を更新する際には
\(W_i := W_i - \eta \frac{\partial f}{\partial W_i}\)
とします。(\(f\)は目的関数で、\(\eta\)は学習率(パラメータ更新のスケールを決めるパラメータ)です。)
def calc_der(x,y,tW,tV,tbs,tb0,acf,acfder):
tdw = np.zeros(nhl)
tdv = np.zeros(nhl)
tdbs = np.zeros(nhl)
tdb0 = 0.0
#以下の勾配の計算は、目的関数が二乗誤差かつ全データでの勾配の和を使用する場合にのみ正しい
for i in range(len(x)):
g = np.dot(tV, acf(tW*x[i]+tbs) ) + tb0 - y[i]
tdb0 += 2.0 * g
for jth in range(nhl):
tdv[jth] += 2.0 * g * acf(tW[jth]*x[i]+tbs[jth])
tdw[jth] += 2.0 * g * tV[jth] * acfder(tW[jth]*x[i]+tbs[jth]) *x[i]
tdbs[jth] += 2.0 * g * tV[jth] * acfder(tW[jth]*x[i]+tbs[jth])
return tdw, tdv, tdbs, tdb0
#シグモイド関数の微分: 勾配の計算を具体的に求めるのに使う
def sigmoid_der(z):
return np.exp(-z)/ ((1.0+np.exp(-z))**2)
さてW,V,bs,b0の初期値での勾配の値は
acf = sigmoid
acfder = sigmoid_der #sigmoid関数の微分sigmoid_derをacfderという名前で使う
calc_der(xt,ny,W,V,bs,b0,acf,acfder)
(array([ 5.21872673e-02, -8.03960749e+00, 1.83009108e+00, 1.91103332e+00,
3.24927634e+00, -7.23670010e+00, -1.12232153e+00, 7.58282404e-03]),
array([36.82875279, 29.24447765, 49.19261588, 9.67161219, 23.84412956,
23.11524231, 35.19158249, 35.04412075]),
array([ 2.14818071e-01, -3.23527933e+01, 9.04076394e+00, 8.00770445e+00,
1.34159140e+01, -2.80674027e+01, -4.66782630e+00, 2.97730658e-02]),
58.69466810466825)
と計算できるようになりました。
def fitGD(x,y,tW,tV,tbs,tb0,acf,acfder,nepoch,eta,verbose):
for i in range(nepoch):
tdw,tdv,tdbs, tdb0 = calc_der(x,y,tW,tV,tbs,tb0,acf,acfder)
tW = tW - eta * tdw
tV = tV -eta * tdv
tbs = tbs -eta * tdbs
tb0 = tb0 -eta * tdb0
if verbose == 1:
print(i, "tloss =", calc_tloss(x,y,tW,tV,tbs,tb0,acf))
return tW,tV,tbs,tb0,tdw,tdv,tdbs, tdb0
では実際に上の関数を使って、パラメータの値を更新してみましょう。
(nhlの値に依りますが、ちょっぴり計算に時間がかかります)
nepoch = 2000
acf = sigmoid; acfder=sigmoid_der
verbose=0
eta = 0.01 #学習率(パラメータ更新のスケールを決めるパラメータ)
W,V,bs,b0,dw,dv,dbs,db0=fitGD(xt,ny,W,V,bs,b0,acf,acfder,nepoch,eta,verbose)
更新された重み・バイアス(W,V,bs,b0)を使って、データとの二乗誤差を計算してみると…
print("学習後の二乗誤差",calc_tloss(xt,ny,W,V,bs,b0,acf))
学習後の二乗誤差 31.426829182338306
すると、さっきより小さくはなっていますが、そこまで二乗誤差が減っていません。
実際にplotしてみても
xp = np.linspace(0, 0.5, 500)
yp = 0.0*xp
for i in range(len(yp)):
yp[i] = np.dot(V, sigmoid(W*xp[i]+bs)) + b0
fig = plt.figure(figsize=(10,4))
ax = fig.add_subplot(111)
ax.set_xlabel("x"); ax.set_ylabel("y")
ax.scatter(xt, yt, facecolor="none", edgecolor="b", s=50, label="Data")
ax.plot(xp,yp*ystd+ymean,label="ANN") ## ニューラルネットワークの出力は標準化した値に対して学習されていることに注意
ax.legend()
plt.show()
plt.close()
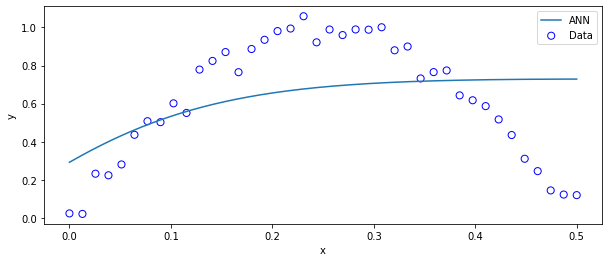
ほとんど学習が進んでいません…(絶望)
学習の様子を都度printしてみる(verbose=1に設定する)ことにして
最初からやりなおしてみると…
np.random.seed(1234)
W = np.random.normal(0.0,1.0,nhl)
V = np.random.normal(0.0,1.0,nhl)
bs = np.random.normal(0.0,1.0,nhl)
b0 = np.random.normal()
nepoch=20 #20回だけ学習の様子を表示
verbose=1
print("学習前のloss", calc_tloss(xt,ny,W,V,bs,b0,acf))
#学習
W,V,bs,b0,dw,dv,dbs,db0=fitGD(xt,ny,W,V,bs,b0,acf,acfder,nepoch,eta,verbose)
学習前のloss 61.29358546868393
0 tloss = 155.20176990047585
1 tloss = 636.6940976770327
2 tloss = 1982.0790483266553
3 tloss = 2056.051066857846
4 tloss = 75.1510373285995
5 tloss = 41.306942787588895
6 tloss = 40.230205073524374
7 tloss = 40.1956281449949
8 tloss = 40.19379266944327
9 tloss = 40.19298621925973
10 tloss = 40.19221490236367
11 tloss = 40.19144755457859
12 tloss = 40.19068317848521
13 tloss = 40.18992172293257
14 tloss = 40.189163166751285
15 tloss = 40.188407489902666
16 tloss = 40.18765467254862
17 tloss = 40.186904695016516
18 tloss = 40.186157537795744
19 tloss = 40.18541318153565
あるところからは、ほとんど学習が進んでいない事がわかります。
原因として考えられるのは
loss functionをパラメータ(超)空間上にプロットした際にプラトーが存在する
最適化手法や学習率の設定が適切でない
初期値が悪い
などがあります。
勾配降下法は、最もシンプルな勾配を使った最適化手法ですが、学習の途中で勾配がほとんど0になってしまって(勾配消失ともいう)、学習が進まなくなってしまう、といったことがよく起こります。
「勾配が小さいなら勾配にかける学習率を大きくすればええんとちゃいまんの…?」
と思うかもしれませんが、学習率を単純に大きくしてしまうと、明後日の方向にパラメータを更新するせいで目的関数が発散してしまいます。(eta=0.1などとして試してみてください)
注) 勾配降下法を拡張した、データを部分的に使うことで学習が停滞することを防ぐ、確率的勾配降下法(Stochastic Gradient Descent; SGD)は現在もよく使われています。
以下では、Adamと呼ばれる別の最適化手法を試してみましょう。
Adam#
Adamは、勾配降下法の様にその都度の勾配の情報だけを使うのではなく、 以前の勾配の情報も有効活用する手法です。
Adamは2014年に提唱された比較的新しい手法で、以降の機械学習の論文では、Adamが最もよく使われています。(*最も”良い”という意味では必ずしもありません)
def updateAdam(A,mt,vt,i,beta1,beta2,eps):
mhat = mt / (1.0-beta1**(i+1))
vhat = vt / (1.0-beta2**(i+1))
return mhat / (np.sqrt( vhat )+eps)
def fitAdam(x,y,tW,tV,tbs,tb0,acf,acfder,nepoch,eta,verbose):
mts = [ np.zeros(nhl), np.zeros(nhl), np.zeros(nhl), np.zeros(1) ]
vts = [ np.zeros(nhl), np.zeros(nhl), np.zeros(nhl), np.zeros(1) ]
## Adamで使用するパラメータ
beta1 = 0.9; beta2 = 0.999; eps = 1.e-6
omb1 = 1.0-beta1; omb2 = 1.0-beta2
## 最適化
for i in range(nepoch):
tmp = calc_der(x,y,tW,tV,tbs,tb0,acf,acfder) ### 勾配を計算するところまでは同じ。
for n,mt in enumerate(mts):
mts[n] = beta1 * mt + omb1 * tmp[n]
vts[n] = beta2 * vts[n] + omb2 * (tmp[n]**2)
### 重み・バイアスの更新
tW += -eta * updateAdam(tW, mts[0],vts[0],i,beta1,beta2,eps)
tV += -eta * updateAdam(tV, mts[1],vts[1],i,beta1,beta2,eps)
tbs += -eta * updateAdam(tbs,mts[2],vts[2],i,beta1,beta2,eps)
tb0 += -eta * (mts[3]/(1.0-beta1**(i+1))) / ( np.sqrt( vts[3]/ (1.0-beta2**(i+1))) + eps)
if verbose and i % 500 == 0:
print(i, "tloss =", calc_tloss(x,y,tW,tV,tbs,tb0,acf))
return tW,tV,tbs,tb0
それでは重みを初期化して、再び学習をしてみましょう
np.random.seed(1234) ## Gradient descentと同条件でスタートするためseedを固定
W = np.random.normal(0.0,1.0,nhl)
V = np.random.normal(0.0,1.0,nhl)
bs = np.random.normal(0.0,1.0,nhl)
b0 = np.random.normal()
nepoch=2000
verbose=False
eta = 0.05
acf = sigmoid ; acfder =sigmoid_der
print("学習前のloss", calc_tloss(xt,ny,W,V,bs,b0,acf))
W,V,bs,b0=fitAdam(xt,ny,W,V,bs,b0,acf,acfder,nepoch,eta,verbose)
print("学習後のloss", calc_tloss(xt,ny,W,V,bs,b0,acf))
学習前のloss 61.29358546868393
学習後のloss [0.89838996]
さっきよりlossの値が小さくなっています。学習がうまく行ってそうですね。
グラフにしてみると…
xp = np.linspace(0, 0.5, 500)
yp = 0.0*xp
for i in range(len(yp)):
yp[i] = np.dot(V, sigmoid(W*xp[i]+bs)) + b0
ytruth = np.sin(2*np.pi*xp)
fig = plt.figure(figsize=(10,4))
ax = fig.add_subplot(111)
ax.set_xlabel("x"); ax.set_ylabel("y")
ax.scatter(xt, yt, facecolor="none", edgecolor="b", s=50, label="Data")
ax.plot(xp,yp*ystd+ymean,color="C01",label="ANN")
ax.plot(xp,ytruth,color="C02",label="Ground Truth")
ax.legend()
plt.show()
plt.close()
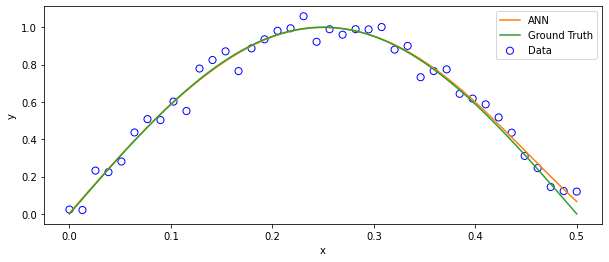
のように、データの特徴をそこそこうまく捉えたニューラルネットワークへと学習が進みました。
実際には、ニューラルネットワークの精度(良さ)は、前述のような検証データに対する汎化性能で評価します。
上で示した例では、3層のニューラルネットワークにデータからそれらしい関数を学習させてみました。
ニューラルネットワークの構造をより複雑化したりしながら、より複雑で高次元な回帰問題に応用したり、回帰問題だけではなく分類問題・画像生成・物体検知などなど、各種の楽しい実社会の問題に応用していきます。 (例: 第2回で説明した敵対的生成ネットワーク)
最適化手法に関するまとめ#
ニューラルネットワークの学習がうまく進むかどうかは一般に
ネットワークの構造(アーキテクチャとも言ったりします)や活性化関数(とその微分)の持つ性質
最適化手法や手法内のパラメータ
重みやバイアスの初期値
などに強く依存します。
1.に関して
回帰問題における代表的な活性化関数としては
最近の傾向として、sigmoidよりも以下のReLU関数が使われることが多いです。
def relu(z):
return (z > 0)* z
def relu_der(z):
return (z > 0)*1.0
#いずれも、zが実数値でもnp.array型のベクトルでも対応可能な表式
##適当な区間のxの値を用意する
xp = np.linspace(-10.0,10.0,100)
yp_sigmoid = sigmoid(xp)
yp_relu = relu(xp)
fig = plt.figure(figsize=(10,4))
ax1 = fig.add_subplot(121)
ax1.plot(xp,yp_sigmoid,label="Sigmoid")
ax1.legend()
ax2 = fig.add_subplot(122)
ax2.plot(xp,yp_relu,label="ReLU")
ax2.legend()
plt.show()
plt.close()
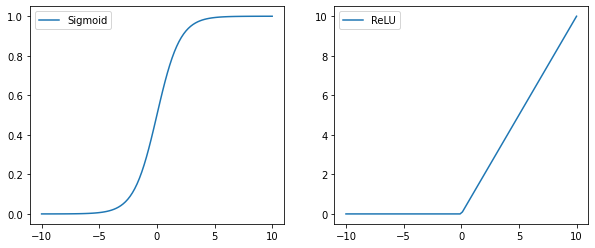
sigmoid関数はx->+∞で1.0, x=-∞で-1.0に漸近します。
一方でReLU関数はx=0までは0.0で、x>0.0で、xとなるような関数です。
なぜReLUがよく使われる様になったかと言うと、
(特に隠れ層の数が多い深層学習において)学習するにつれて勾配の値が小さくなって学習が進まない、
という問題を解決するためです。
それぞれの関数の微分を表示してみると
xp = np.linspace(-10.0,10.0,100)
yp_sigmoid = sigmoid_der(xp)
yp_relu = relu_der(xp)
fig = plt.figure(figsize=(10,4))
ax1 = fig.add_subplot(121)
ax1.plot(xp,yp_sigmoid,label="Sigmoid")
ax1.legend()
ax2 = fig.add_subplot(122)
ax2.plot(xp,yp_relu,label="ReLU")
ax2.legend()
plt.show()
plt.close()
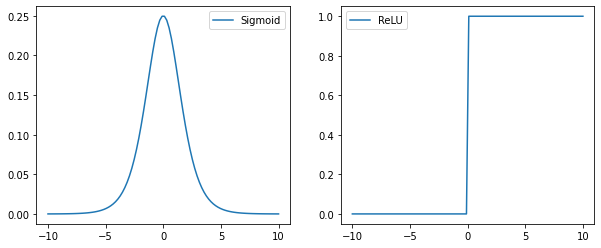
sigmoid関数は微分の値が最大で0.25なのに対して、ReLU関数では最大1.0となるため勾配の消失が起こりにくいのです。
問題ごとに何が最適なネットワーク構造だったり活性化関数なのかは、
予め分かることはなく、試行錯誤が必要です。
ここまでこの授業で勉強してきた皆さんは既に、
「この試行錯誤自体を人力ではなくコンピュータにやらせる方法はないか」という点に思い至るのではないでしょうか?
これに関連したお話はベイズ最適化の回で説明します。
3.に関して
また、ネットワークの重みやバイアスをどのような値から始めるかに学習が依存する場合もあります。
というのも、今考えた3層のニューラルネットワークでは、
重み\(W\)の学習に使う勾配の表式は、\(V\)に比例しています。
したがって単純に勾配の情報のみを使う最適化手法では、
\(V\)の初期値を0に取ったり、学習の過程で偶然\(V\)の値が0に近くなってしまうと、
\(V\)が更新されノンゼロの値を持つまで\(W\)の学習は始まりません。
どのような初期値を採用するべきかに関しても、予め知ることは一般にはできませんが、
いくつかの特定の場合に関して、推奨される方法というのは存在しています。
例: ReLU関数を活性化関数に使うときはHeの初期値というものが推奨されている